Guide: Setting up a CSV validator
Track |
|---|
This guide walks you through the points to consider when setting up CSV validation based on a Table Schema specification and the steps to bring your validation service online.
Note
The CSV validator source code is available on Github, with stable and daily releases published on the Docker Hub. For requests and support please post an issue, or get in touch via email at DIGIT-ITB@ec.europa.eu.
What you will achieve
At the end of this guide you will have understood what you need to consider when starting to implement validation services for your CSV-based specification. You will also have gone through the steps to bring it online and make it available to your users.
A CSV validation service can be created using multiple approaches depending on your needs. You can have an on-premise (or local to your workstation) service through Docker or use the Test Bed’s resources and, with minimal configuration, bring online a public service that is automatically kept up-to-date.
For the purpose of this guide you will be presented the options to consider and start with a Docker-based instance that could be replaced (or complemented) by a setup through the Test Bed. Interestingly, the configuration relevant to the validator is the same regardless of the approach you choose to follow.
What you will need
About 30 minutes.
A text editor.
A web browser.
Access to the Internet.
Docker installed on your machine (only if you want to run the validator as a Docker container).
A basic understanding of CSV and Table Schema. CSV itself is quite simple as a concept but if you want deeper and more formal information you can check its relevant RFC (RFC-4180). Table Schema is a popular means of specifying CSV content and is also simple to get into. The Table Schema specification itself offers a good introduction to its purpose and approach.
How to complete this guide
The steps described in this guide are for the most part hands-on, resulting in you creating a fully operational validation service. For these practical steps there are no prerequisites and the content for all files to be created are provided in each step. In addition, if you choose to try your setup as a Docker container you will also be issuing commands on a command line interface (all commands are provided and explained as you proceed).
Steps
You can complete this guide by following the steps described in this section. Not all steps are required, with certain ones being optional or complementary depending on your needs. The following diagram presents an overview of all steps highlighting the ones that apply in all cases (marked as mandatory):
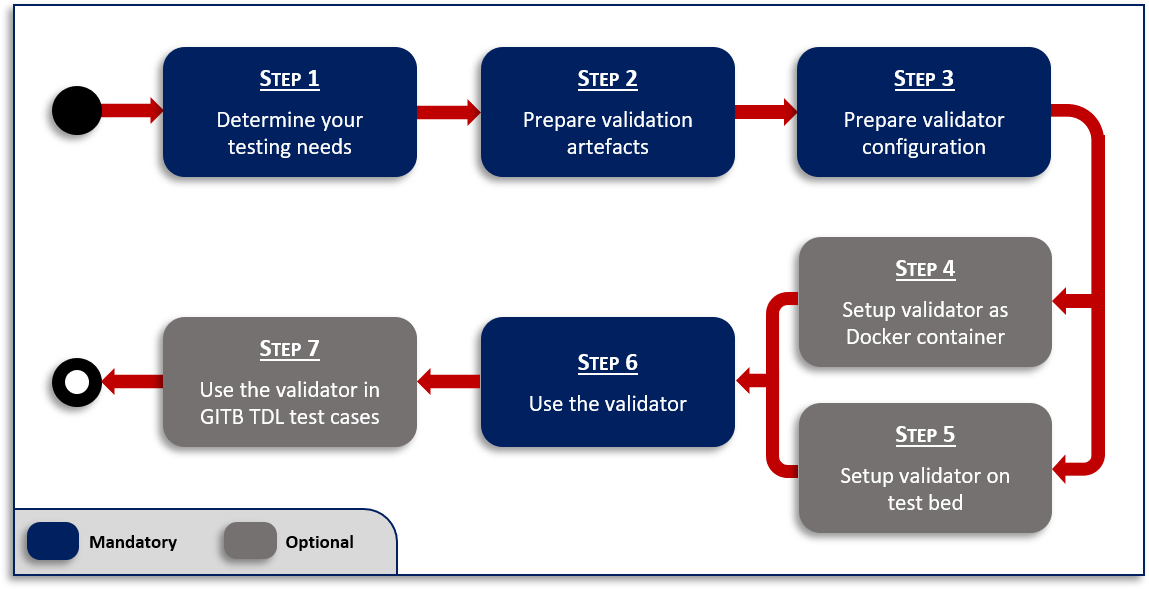
When and why you should skip or consider certain steps depends on your testing needs. Each step’s description covers the options you should consider and the next step(s) to follow depending on your choice.
Step 1: Determine your testing needs
Before proceeding to setup your validator you need to clearly determine your testing needs. A first outline of the approach to follow would be provided by answering the following questions:
Will the validator be available to your users as a tool to be used on an ad-hoc basis?
Do you plan on measuring the conformance of your community’s members to the CSV-based specification?
Is the validator expected to be used in a larger conformance testing context (e.g. during testing of a message exchange protocol)?
Should the validator be publicly accessible?
Should test data and validation reports be treated as confidential?
The first choice to make is on the type of solution that will be used to power your validation service:
Standalone validator: A service allowing validation of CSV content based on a predefined configuration of Table Schemas. The service supports fine-grained customisation and configuration of different validation types (e.g. specification versions) and supported communication channels. Importantly, use of the validator is anonymous and it is fully stateless in that none of the test data or validation reports are maintained once validation completes.
Complete Test Bed: The Test Bed is used to realise a full conformance testing campaign. It supports the definition of test scenarios as test cases, organised in test suites that are linked to specifications. Access is account-based allowing users to claim conformance to specifications and execute in a self-service manner their defined test cases. All results are recorded to allow detailed reporting, monitoring and eventually certification. Test cases can address CSV validation but are not limited to that, allowing validation of any complex exchange of information.
It is important to note that these two approaches are by no means exclusive. It is often the case that a standalone validator is defined as a first step that is subsequently used from within test cases in the Test Bed. The former solution offers a community tool to facilitate work towards compliance supporting ad-hoc data validation, whereas the latter allows for rigorous conformance testing to take place where proof of conformance is required. This could apply in cases where conformance is a qualification criterion before receiving funding or before being accepted as a partner in a distributed system. Finally, it is interesting to consider that non-trivial CSV validation may involve multiple validation artefacts (e.g. different schemas for different message types). In such a case, even if ad-hoc data validation is not needed, defining a separate validator simplifies management of the validation artefacts by consolidating them in a single location, as opposed to bundling them within test suites.
Regardless of the choice of solution, the next point to consider will be the type of access. If public access is important then the obvious choice is to allow access over the Internet. An alternative would be an installation that allows access only through a restricted network, be it an organisation’s internal network or a virtual private network accessible only by your community’s members. Finally, an extreme case would be access limited to individual workstations where each community member would be expected to run the service locally (albeit of course without the expectation to test message exchanges with remote parties).
If access to your validation services over the Internet is preferred or at least acceptable, the simplest case is to opt for using the shared DIGIT Test Bed resources, both regarding the standalone validator and the Test Bed itself. If such access is not acceptable or is technically not possible (e.g. access to private resources is needed), the proposed approach would be to go for a Docker-based on-premise installation of all components.
Summarising the options laid out in this section, you will first want to choose:
Whether you will be needing a standalone validator, a complete Test Bed or both.
Whether the validator and/or Test Bed will be accessible over the Internet or not.
Your choices here can help you better navigate the remaining steps of this guide. Specifically:
Step 2: Prepare validation artefacts and Step 3: Prepare validator configuration can be skipped if you just want a quick deployment for testing with a generic validator that allows you to upload your own schemas before validating.
Step 4: Setup validator as Docker container can be skipped if you are interested only in a public service or if you plan to only use the validator as part of conformance testing scenarios (i.e. within the Test Bed).
Step 5: Setup validator on Test Bed can be skipped if a publicly accessible service is not an option for you.
Step 7: Use the validator in GITB TDL test cases can be skipped if you only want data validation without additional conformance testing scenarios.
Step 2: Prepare validation artefacts
As an example case for CSV validation we will consider a variation of the EU purchase order case first seen in Guide: Creating a test suite. In short, for the purposes of this guide you are considered to be leading an EU cross-border initiative to define a new common specification for the exchange of purchase orders between retailers.
To facilitate bulk imports of purchase orders your experts have created the following Table Schema:
{
"fields": [
{
"name": "shippingAddressName",
"type": "string",
"description": "The shipping address recipient name",
"constraints": {
"required": true
}
},
{
"name": "shippingAddressStreet",
"type": "string",
"description": "The shipping address street",
"constraints": {
"required": true
}
},
{
"name": "shippingAddressCity",
"type": "string",
"description": "The shipping address city",
"constraints": {
"required": true
}
},
{
"name": "shippingAddressZip",
"type": "string",
"description": "The shipping address ZIP code",
"constraints": {
"required": true
}
},
{
"name": "billingAddressName",
"type": "string",
"description": "The billing address recipient name",
"constraints": {
"required": true
}
},
{
"name": "billingAddressStreet",
"type": "string",
"description": "The billing address street",
"constraints": {
"required": true
}
},
{
"name": "billingAddressCity",
"type": "string",
"description": "The billing address city",
"constraints": {
"required": true
}
},
{
"name": "billingAddressZip",
"type": "string",
"description": "The billing address ZIP code",
"constraints": {
"required": true
}
},
{
"name": "orderDate",
"type": "date",
"description": "The date the purchase order was created",
"format": "%Y-%m-%d",
"constraints": {
"required": true
}
},
{
"name": "comment",
"type": "string",
"description": "An optional comment included in the purchase order",
"constraints": {
"maxLength": 500
}
},
{
"name": "totalItemQuantity",
"type": "integer",
"description": "The total quality of items included in the purchase order",
"constraints": {
"required": true,
"minimum": 0
}
},
{
"name": "totalItemCostEUR",
"type": "number",
"description": "The total cost (in EUR) of the purchase order's items",
"decimalChar": ".",
"constraints": {
"required": true,
"minimum": 0.0
}
}
]
}
Based on this, a sample CSV file containing purchase orders would be as follows:
shippingAddressName,shippingAddressStreet,shippingAddressCity,shippingAddressZip,billingAddressName,billingAddressStreet,billingAddressCity,billingAddressZip,orderDate,comment,totalItemQuantity,totalItemCostEUR
John Doe,Europa Avenue 123,Brussels,1000,Jane Doe,Europa Avenue 210,Brussels,1000,2020-01-22,Send in one package please,35,40.99
John Doe,Europa Avenue 123,Brussels,1000,Jane Doe,Europa Avenue 210,Brussels,1000,2020-01-23,,12,120.50
John Doe,Europa Avenue 123,Brussels,1000,Jane Doe,Europa Avenue 210,Brussels,1000,2020-01-24,,5,10.30
In addition to this basic specification, your business requirements also define the concept of large purchase orders which are those that include more than 10 items. The same requirements foresee that data imports should be possible for any kind of order or only refer to orders considered as large. To capture this additional requirement we will define a copy of the base Table Schema specification in which we will ensure that the included items for each order are always more than 10. The Table Schema to reflect this would be as follows (the minimum expectation is highlighted below):
{
"fields": [
{
"name": "shippingAddressName",
"type": "string",
"description": "The shipping address recipient name",
"constraints": {
"required": true
}
},
{
"name": "shippingAddressStreet",
"type": "string",
"description": "The shipping address street",
"constraints": {
"required": true
}
},
{
"name": "shippingAddressCity",
"type": "string",
"description": "The shipping address city",
"constraints": {
"required": true
}
},
{
"name": "shippingAddressZip",
"type": "string",
"description": "The shipping address ZIP code",
"constraints": {
"required": true
}
},
{
"name": "billingAddressName",
"type": "string",
"description": "The billing address recipient name",
"constraints": {
"required": true
}
},
{
"name": "billingAddressStreet",
"type": "string",
"description": "The billing address street",
"constraints": {
"required": true
}
},
{
"name": "billingAddressCity",
"type": "string",
"description": "The billing address city",
"constraints": {
"required": true
}
},
{
"name": "billingAddressZip",
"type": "string",
"description": "The billing address ZIP code",
"constraints": {
"required": true
}
},
{
"name": "orderDate",
"type": "date",
"description": "The date the purchase order was created",
"format": "%Y-%m-%d",
"constraints": {
"required": true
}
},
{
"name": "comment",
"type": "string",
"description": "An optional comment included in the purchase order",
"constraints": {
"maxLength": 500
}
},
{
"name": "totalItemQuantity",
"type": "integer",
"description": "The total quality of items included in the purchase order",
"constraints": {
"required": true,
"minimum": 10
}
},
{
"name": "totalItemCostEUR",
"type": "number",
"description": "The total cost (in EUR) of the purchase order's items",
"decimalChar": ".",
"constraints": {
"required": true,
"minimum": 0.0
}
}
]
}
Given these requirements and validation artefacts we want to support two types of validation (or profiles):
basic: For CSV files including any kind of purchase orders. This is realised by validating against
PurchaseOrder.schema.json.large: For CSV files including only large purchase orders. This is realised by validating against
PurchaseOrder-large.schema.json.
As the first configuration step for the validator we will prepare a folder with the required resources. For this purpose create a root
folder named validator with the following subfolders and files:
validator
└── resources
└── order
└── schemas
├── PurchaseOrder.schema.json
└── PurchaseOrder-large.schema.json
Regarding the PurchaseOrder.schema.json and PurchaseOrder-large.schema.json files you can create them from the above content. Note that you are free to use any names for the
files and folders; the ones used here will however be the ones considered in this guide’s subsequent steps.
Step 3: Prepare validator configuration
After having defined your testing needs and the validation artefacts for your specific case, the next step will be to configure the validator. The validator is defined by a core engine maintained by the Test Bed team and a layer of configuration, provided by you, that defines its use for a specific scenario. In terms of features the validator supports the following:
Validation channels including a REST web service API, a SOAP web service API, a web user interface and a command-line tool.
Configuration of Table Schemas to drive the validation that can be local or remote.
Definition of different validation types as logically-related sets of validation artefacts.
Support per validation type allowing a user-provided schema.
Support per validation type of CSV syntax settings that can also be set by users at validation time.
Definition of separate validator configurations that are logically split but run as part of a single validator instance. Such configurations are termed “validation domains”.
Customisation of all texts presented to users.
Configuration is provided by means of key-value pairs in a property file. This file can be named as you want but needs to
end with the .properties extension. In our case we will name this config.properties and place it within the order folder.
Recall that the purpose of this folder is to store all resources relevant to purchase order validation. These are the validation
artefacts themselves (PurchaseOrder.schema.json and PurchaseOrder-large.schema.json) and the configuration file (config.properties).
Define the content of the config.properties file as follows:
# The different types of validation to support. These values are reflected in other properties.
validator.type = basic, large
# Labels to describe the defined types.
validator.typeLabel.basic = Basic purchase orders
validator.typeLabel.large = Large purchase orders
# Validation artefacts (Table Schema) to consider for the "basic" type.
validator.schemaFile.basic = schemas/PurchaseOrder.schema.json
# Validation artefacts (Table Schema) to consider for the "large" type.
validator.schemaFile.large = schemas/PurchaseOrder-large.schema.json
# The title to display for the validator's user interface.
validator.uploadTitle = Purchase Order Validator
All validator properties share a validator. prefix. The validator.type property is key as it defines one or more types of
validation that will be supported (multiple are provided as a comma-separated list of values). The values provided here are important
not only because they define the available validation types but also because they drive most other configuration properties.
Regarding the schemas to use, these are provided by means of validator.schemaFile.TYPE properties, where the
TYPE placeholder corresponds to the validation type they map to. These properties take one or more (comma-separated) file paths
(relative to the configuration file) to lookup schema files. Using these properties you define the validator’s schemas
through local files, where provided paths can be for a file or a folder. If a folder is referenced it will load all contained top-level
files (i.e. ignoring subfolders).
Note
Further schema configuration: You may also define schemas as remote resource references and/or as being user-provided.
The purpose of the remaining properties is to customise the text descriptions presented to users:
validator.typeLabeldefines a label to present to users on the validator’s user interface for the type in question.
validator.uploadTitledefines the title label to present to users on the validator’s user interface.
Once you have created the config.properties file, the validator folder should be as follows:
validator
└── resources
└── order
├── schemas
│ ├── PurchaseOrder.schema.json
│ └── PurchaseOrder-large.schema.json
└── config.properties
As part of the validator’s configuration you may also define further aspects of your CSV syntax that are not addressed by the Table Schema
specification. An example of such aspects are whether or not CSV content is expected to include a first header row, the character that
is used as a field delimiter, and the character used as a quote (to wrap a field’s value). In our case we didn’t specify these as
we have relied on the default settings, i.e. always expected headers, the , character as a field delimiter, and the " character as the
quote. Such settings can be adapted per validation type using the validator.hasHeaders, validator.delimiter and validator.quote
properties. For example, if we wanted to use the pipe character (|) to separate fields instead of the default comma (,) and never expect
a header row we could adapt the configuration as follows:
validator.type = basic, large
...
validator.hasHeaders.basic = false
validator.hasHeaders.large = false
validator.delimiter.basic = |
validator.delimiter.large = |
Furthermore, if you want to offer flexibility to users in defining such syntax settings you can also allow them to specify them as part of
their provided input. This is achieved through the validator.input.hasHeader, validator.input.delimiter and validator.input.quote properties
that similarly per validation type define whether users may choose their own settings. In each case the option you can specify here is to
prevent such input (none, the default), allow it as optional (optional) or require it as mandatory (required). Returning to our earlier
example we can further extend the configuration by allowing users to define themselves whether their content includes a header row. This is
achieved as follows:
validator.type = basic, large
...
validator.input.hasHeaders.basic = optional
validator.input.hasHeaders.large = optional
If no user input on such settings is requested or provided, the defaults you have specified will apply.
The limited configuration file we have prepared assumes numerous default configuration properties. An important example is that by default, the validator
will expose a web user interface, SOAP web service API and REST web service API. This configuration is driven through the validator.channels property that
by default is set to form, soap_api, rest_api (for a user form and SOAP web service respectively). All configuration properties provided in
config.properties relate to the specific domain in question, notably purchase orders, reflected in the validator’s resources as the
order folder. Although rarely needed, you may define additional validation domains each with its own set of validation artefacts and
configuration file (see Configuring additional validation domains for details on this). Finally, if you
are planning to host your own validator instance you can also define configuration at the level of the complete validator
(see Additional configuration options regarding application-level configuration options).
For the complete reference of all available configuration properties and their default values refer to section Validator configuration properties.
Remote schemas
Defining the validator’s schemas as local files is not the only option. If these are available online you can also reference them remotely
by means of validator.schemaFile.TYPE.remote.N.url properties. The N element in the properties’ names is a zero-based positive integer allowing you to define more
than one entries to match the number of remote files.
The example that follows illustrates the loading of a schema for a validation type named v2.2.1 from a remote location:
validator.type = v2.2.1
...
validator.schemaFile.v2.2.1.remote.0.url = https://my.server.com/my_schema_1.json
If remote schema lookups require authentication, the approach to follow is defined through the optional authType sub-property.
The following table summarises its supported values and additional settings per case:
Value |
Description |
|---|---|
|
Use HTTP Basic authentication. Additional |
|
Use a custom HTTP header. Additional |
|
Use OAuth 2.0 with a client credentials grant. An additional |
For the oauth case in particular and referring to the serviceId property, this is used to point to the configuration of an OAuth
service defined separately in the validator’s configuration. Several such services can be configured, providing for each
a set of properties as follows:
validator.oAuthService.SERVICE.clientIdfor the client identifier to use.validator.oAuthService.SERVICE.clientSecretfor the client secret to use.validator.oAuthService.SERVICE.tokenUrlfor the token retrieval URL.
The SERVICE placeholder in the above properties is the internal identifier you will use to refer to
this service from your remote schema entries. Defining multiple services allows you to use several OAuth services, referencing each one
for the schemas that need them. The validator will internally manage and refresh authentication tokens, before
automatically including them in requests.
Note
You can use environment variables to hide sensitive authentication properties.
The following example shows how to specify authentication for remote schema retrieval of different validation types (type1,
type2, type3 and type4) using each of the discussed approaches.
# Case 1: Remote schema for which no authentication is needed.
validator.schemaFile.type1.remote.0.url = https://my.server.com/my_rules_1.json
# Case 2: Remote schema for which HTTP Basic authentication will be used.
# The username and password are provided through environment variables.
validator.schemaFile.type2.remote.0.url = https://my.server.com/my_rules_2.json
validator.schemaFile.type2.remote.0.authType = basic
validator.schemaFile.type2.remote.0.username = ${env:VALIDATOR_USERNAME}
validator.schemaFile.type2.remote.0.password = ${env:VALIDATOR_PASSWORD}
# Case 3: Remote schema for which a custom 'X-API-KEY' HTTP header will be used for authentication.
# The value of the header is provided through an environment variable.
validator.schemaFile.type3.remote.0.url = https://my.server.com/my_rules_3.json
validator.schemaFile.type3.remote.0.authType = header
validator.schemaFile.type3.remote.0.headerName = X-API-KEY
validator.schemaFile.type3.remote.0.headerValue = ${env:VALIDATOR_API_KEY}
# Case 4: Remote schema for which OAuth 2.0 will be used for authentication.
# The referenced 'myOAuthService' service is defined below.
validator.schemaFile.type4.remote.0.url = https://my.server.com/my_rules_4.json
validator.schemaFile.type4.remote.0.authType = oauth
validator.schemaFile.type4.remote.0.serviceId = myOAuthService
# OAuth service configuration. The 'myOAuthService' can be referenced for several resources.
# The client ID and secret are provided through environment variables.
validator.oAuthService.myOAuthService.clientId = ${env:VALIDATOR_CLIENT_ID}
validator.oAuthService.myOAuthService.clientSecret = ${env:VALIDATOR_CLIENT_SECRET}
validator.oAuthService.myOAuthService.tokenUrl = http://my.service.org/oauth/token
In case remote schemas fail to be retrieved, due to authentication problems or other issues, you may choose to report this to your users. This is achieved by using property
validator.validator.remoteArtefactLoadErrors.TYPE to adapt this for a given validation type, or validator.validator.remoteArtefactLoadErrors
to set your default approach (see Domain-level configuration). The values you may set are:
fail, to log the error, immediately stop validation and report this as an error to the user.warn, to log the error, continue validation, but display a warning to the user.log, considered by default, to log the error but continue validation without notifying the user.
Although rare you may also combine local and remote schema files by defining a validator.schemaFile.TYPE property and one or more validator.schemaFile.TYPE.remote.N.url
properties. In all cases, the schemas from all sources will be used for the validation.
Note
Remote schema caching: Caching is used to avoid constant lookups of remote schema files. Once loaded, remote schemas will be automatically refreshed every hour.
User-provided schemas
Another available option on schema file configuration is to allow a given validation type to support a user-provided schema. Such a schema would be considered in
addition to any pre-configured local and remote schemas. Enabling user-provided schemas is achieved through the validator.externalSchema property:
...
validator.externalSchema.TYPE = required
These properties allow three possible values:
required: The relevant schema(s) must be provided by the user.
optional: Providing the relevant schema(s) is allowed but not mandatory.
none(the default value): No such schema(s) are requested or considered.
Note
User-provided schemas are prevented from importing internal resources unless explicitly whitelisted via the
application-level property validator.allowedUriImports.
For remotely-retrieved schemas that require authentication, the approach to follow is defined through the optional authType sub-property as in the
case of authenticating pre-configured remote schemas. The following table
summarises its supported values and additional settings per case:
Value |
Description |
|---|---|
|
Use HTTP Basic authentication. Additional |
|
Use a custom HTTP header. Additional |
|
Use OAuth 2.0 with a client credentials grant. An additional |
The following example shows how to specify authentication for user-provided schemas of different validation types (custom1,
custom2, custom3 and custom4) using each of the discussed approaches.
# Case 1: No authentication is needed.
validator.externalSchemas.custom1 = required
# Case 2: Use HTTP Basic authentication.
# The username and password are provided through environment variables.
validator.externalSchema.custom2 = required
validator.externalSchema.custom2.authType = basic
validator.externalSchema.custom2.username = ${env:VALIDATOR_USERNAME}
validator.externalSchema.custom2.password = ${env:VALIDATOR_PASSWORD}
# Case 3: Use a custom 'X-API-KEY' HTTP header.
# The value of the header is provided through an environment variable.
validator.externalSchema.custom3 = required
validator.externalSchema.custom3.authType = header
validator.externalSchema.custom3.headerName = X-API-KEY
validator.externalSchema.custom3.headerValue = ${env:VALIDATOR_API_KEY}
# Case 4: Use OAuth 2.0 will be used for authentication.
# The referenced 'myOAuthService' service is defined below.
validator.externalSchema.custom4 = required
validator.externalSchema.custom4.authType = oauth
validator.externalSchema.custom4.serviceId = myOAuthService
# OAuth service configuration. The 'myOAuthService' can be referenced for several resources.
# The client ID and secret are provided through environment variables.
validator.oAuthService.myOAuthService.clientId = ${env:VALIDATOR_CLIENT_ID}
validator.oAuthService.myOAuthService.clientSecret = ${env:VALIDATOR_CLIENT_SECRET}
validator.oAuthService.myOAuthService.tokenUrl = http://my.service.org/oauth/token
Note
The configured authentication approach applies for all schema lookups, including the initial request (if provided as a URI), as well as internal references.
Specifying that for a given validation type you allow users to provide a schema will result in it being combined with your pre-defined one (if present). This could be useful in scenarios where you want to define a common validation base but allow also ad-hoc extensions for e.g. restrictions defined at user-level (e.g. National validation rules to consider in addition to a common set of EU rules).
Note
Generic validator: It is possible to not predefine any schema resulting in a validator that is truly generic, expecting schemas to be provided by users. Such a generic instance actually exists at https://www.itb.ec.europa.eu/csv/any/upload. This generic validator will automatically be set up if you don’t specify validator configurations.
Supporting options per validation type
The different types of validation supported by the validator (enumerated using property validator.type) determine the different
kinds of validation that your users may select. Available types are listed in the validator’s web user interface
in a dropdown list, and need to be provided as input when executing a validation.
It could be the case that your validator needs to support an extra level of granularity over the validation types. This would apply if each validation type has itself a set of additional options that actually define the specific validation to take place. For example, a validator for a specification defining rules for different types of data structures, may need to also allow users to select the desired version number. In this case we would define:
As validation types, the specification’s foreseen data structures.
As validation type options, the version numbers for each data structure.
Configuring such options can greatly simplify a validator’s configuration given that certain common data needs to be defined only once. In addition, the validator’s user interface becomes much more intuitive by listing two dropdowns in place of one: the first one to select the validation type, and the second one to select it’s specific option. The alternative, simply configuring all combinations as separate validation types, would render the validator less intuitive and more difficult to maintain.
Options are defined per validation type using validator.typeOptions.TYPE properties, for which the applicable options
are defined as a string with comma-separated values. Once options are defined, most configuration properties that are specific
to validation types now consider the full type as TYPE.OPTION (type followed by option and separated by .).
In terms of defining labels for options we can use:
validator.typeOptionLabel.TYPE.OPTION, for the label of an option specific to a given validation type.
validator.optionLabel.OPTION, for the label of an option that is the same across types.
validator.completeTypeOptionLabel.TYPE.OPTION, for a label to better express the combination of type plus option.
Revisiting our EU Purchase Order example we could add support for specification versions by configuring properties as follows (we skip defining labels as the option value suffices):
# Validation types
validator.type = basic, large
validator.typeLabel.basic = Basic purchase order
validator.typeLabel.large = Large purchase order
# Options
validator.typeOptions.basic = v1.2.0, v1.1.0, v1.0.0
validator.typeOptions.large = v1.1.0, v1.0.0
# Validation artefacts
validator.schemaFile.basic.v1.2.0 = schemas/v1.2.0/PurchaseOrder.schema.json
validator.schemaFile.basic.v1.1.0 = schemas/v1.1.0/PurchaseOrder.schema.json
validator.schemaFile.basic.v1.0.0 = schemas/v1.0.0/PurchaseOrder.schema.json
validator.schemaFile.large.v1.1.0 = schemas/v1.1.0/PurchaseOrder-large.schema.json
validator.schemaFile.large.v1.0.0 = schemas/v1.0.0/PurchaseOrder-large.schema.json
Note
The configuration property reference specifies per property whether it expects the validation type, option or full type (validation type plus option) as part of its definition.
Presenting validation types in groups
Similar to supporting validation type options you can also add further organisation to your proposed validation types by means of validation type groups. These groups apply to the validator’s web user interface by presenting your validation types in separate sets. Such sets could refer to different families of specifications, different solutions, or anything basically that has a grouping meaning in the context of your validator. Configuring groups has no effect on how validation artefacts are set up, nor on other properties that apply to specific validation types.
To define groups you include in your configuration one or more validator.typeGroup.GROUP entries, set to the list of
validation types the group includes. You may also provide a user-friendly name for each group through validator.typeGroupLabel.GROUP
properties.
Given that the groups’ purpose is specific to your validator, you also have several options on how these are presented. Groups can be displayed as:
Inline elements included as option groups in the validation types’ dropdown list.
A separate dropdown list presented as a selection step before selecting a validation type.
To specify the groups’ presentation approach you define property validator.typeGroupPresentation, set as
inline (the default, presenting groups within the validation type dropdown list), or split (presenting groups in
a separate dropdown). In the latter case you would typically also want to override the label of the groups’ dropdown list
through property validator.label.typeGroupLabel (the default label being “Group”).
Revisiting our EU Purchase Order example we could include groups to split the available types in “production” and “development” modes, the latter including an “experimental” configuration. The following properties illustrate how this could be achieved:
...
validator.type = basic, large, experimental
validator.typeOptions.basic = v2.1.0, v2.0.0, v1.2.0, v1.1.0
validator.typeOptions.large = v2.1.0, v2.0.0
# Define 'prod' and 'dev' groups.
validator.typeGroup.prod = basic, large
validator.typeGroup.dev = experimental
# Label the groups accordingly.
validator.typeGroupLabel.prod = Production
validator.typeGroupLabel.dev = Development
# Present a separate dropdown with the groups (as opposed to inline).
validator.typeGroupPresentation = split
# Override the groups' dropdown label.
validator.label.typeGroupLabel = Validation mode
Note
When using groups all validation types must be mapped to groups otherwise the domain’s configuration is considered invalid.
Validation type aliases
Validation type aliases are alternative ways of referring to the configured validation types. They become meaningful when users refer directly to specific types, such as when using the validator’s REST API, SOAP API or REST API. Typical use cases for aliases would be:
To define an additional “latest” alias that always points to the latest version of your specifications.
To enable backwards compatibility when validation types are reorganised in a configuration update.
To define a validator alias add one or more validator.typeAlias.ALIAS properties where ALIAS is the alias you want to define. As the value of the property you set the target validation type.
Note
Validator aliases refer to full validation types, meaning the combination of validation type and option (TYPE.OPTION).
As an example consider the following configuration:
validator.type = basic, large, preview
validator.typeOptions.basic = v2.1.0, v2.0.0
validator.typeOptions.large = v2.1.0, v2.0.0
The available full validation types based on these properties are basic.v2.1.0, basic.v2.0.0, large.v2.1.0, large.v2.0.0 and preview.
Based on this example we can consider that you may want to add aliases named basic_latest and large_latest for the latest versions of each supported profile. To do so extend your configuration with the following properties:
validator.typeAlias.basic_latest = basic.v2.1.0
validator.typeAlias.large_latest = large.v2.1.0
Doing so you allow clients of your APIs that are interested in always validating against the latest specifications, to do so by referring to these aliases. Otherwise, if new versions where introduced they would need to adapt their implementation.
Domain aliases
Domain aliases are similar in concept to validation type aliases in that they allow you to adapt the validation to carry out based on the user’s request. Simply put, a user requests validation A and you internally carry out validation B.
Domain aliases however, have a a fundamentally different purpose. They are used to delegate requests to a completely separate validator configuration, defined as a separate domain. This means that not only requested validation types are adapted, but also that the complete validator configuration is loaded from the aliased domain. In this case, if domain A is defined as an alias for domain B, any requests to domain A are effectively redirected to domain B. This is not an actual web redirection mind you, although practically the result is similar.
The main reason to define an alias for a domain is to cover validator migrations and consolidations. This typically becomes interesting if you have defined several distinct validators over time, but want to now consolidate all these into a single one to provide a unified user experience. Aggregating validation artefacts into a single validator is easily achieved and then exposing them nicely organised using groups, validation types and options.
While creating the consolidated validator is straightforward, you need to consider the existing users of the now legacy validator domains. This is where aliases come in, as they allow continued use of the legacy domains, while transparently delegating to the correct, consolidated, one. Importantly, this delegation covers all validator APIs (web user interface, REST API and SOAP API).
A domain alias is defined using the validator.domainAlias property, set with the name of the domain to delegate to.
Complementing this, you can also define a set of validator.domainAlias.TYPE properties so that you can map your current
validation types to their equivalent types in the target domain. Note that the TYPE postfix added to these properties
must be the full validation type (validation type and option separated by a dot .), pointing similarly to the
full validation type or an alias in the target domain. Mappings can
be omitted for validation types having the same identifier in both the current and target domains.
Note
In case validation types of the current domain cannot be fully mapped to the target, the entire domain alias configuration is ignored and the validator outputs relevant warnings to its log.
To illustrate how domain aliases work with an example, let’s revisit our fictional purchase order validator, defined
through an order domain with a configuration as follows:
# Title
validator.uploadTitle = Purchase Order Validator
# Validation types
validator.type = basic, large
# Options per type.
validator.typeOptions.basic = v1.1.0, v1.0.0
validator.typeOptions.large = v1.1.0, v1.0.0
# Validation artefact mappings
validator.schemaFile.basic.v1.1.0 = schemas/PurchaseOrder_v1.1.0.json
validator.schemaFile.basic.v1.0.0 = schemas/PurchaseOrder_v1.0.0.json
validator.schemaFile.large.v1.1.0 = schemas/PurchaseOrder_v1.1.0.json
validator.schemaFile.large.v1.0.0 = schemas/PurchaseOrder_v1.0.0.json
Now consider that alongside the purchase order validator you have also defined an invoice validator in a separate invoice domain:
# Title
validator.uploadTitle = Invoice Validator
# Validation types
validator.type = full, summary
# Validation artefact mappings
validator.schemaFile.full = schemas/Invoice.json
validator.schemaFile.summary = schemas/Invoice.json
In terms of filesystem configuration for the order and invoice domains, the validator’s resources are defined as follows:
validator
└── resources
├── order
│ ├── schemas
│ │ ├── PurchaseOrder_v1.1.0.json
│ │ └── PurchaseOrder_v1.0.0.json
│ └── config.properties
└── invoice
├── schemas
│ └── Invoice.json
└── config.properties
You now want to group both validators into a new, consolidated ecommerce validator, defined through an ecommerce domain.
This domain includes all purchase order and invoice artefacts, introducing groups
as a first selection for the document type to validate. The configuration file of this domain will be as follows:
# Title
validator.uploadTitle = eCommerce Validator
# Validation types
validator.type = order_basic, order_large, invoice_full, invoice_summary
# Options per purchase order type.
validator.typeOptions.order_basic = v1.1.0, v1.0.0
validator.typeOptions.order_large = v1.1.0, v1.0.0
# Validation type groups
validator.typeGroup.order = order_basic, order_large
validator.typeGroup.invoice = invoice_full, invoice_summary
validator.typeGroupLabel.order = Purchase order
validator.typeGroupLabel.invoice = Invoice
validator.typeGroupPresentation = split
validator.label.typeGroupLabel = Document type
# Validation artefact mappings for purchase orders
validator.schemaFile.order_basic.v1.1.0 = order/schemas/PurchaseOrder_v1.1.0.json
validator.schemaFile.order_basic.v1.0.0 = order/schemas/PurchaseOrder_v1.0.0.json
validator.schemaFile.order_large.v1.1.0 = order/schemas/PurchaseOrder_v1.1.0.json
validator.schemaFile.order_large.v1.0.0 = order/schemas/PurchaseOrder_v1.0.0.json
# Validation artefact mappings for invoices
validator.schemaFile.invoice_full = invoice/schemas/Invoice.json
validator.schemaFile.invoice_summary = invoice/schemas/Invoice.json
We will now revisit the purchase order and invoice validator configurations, to ensure existing users can seamlessly
transition to the new ecommerce validator. This is achieved by defining a domain alias per case. The order domain’s
configuration is extended as follows:
validator.uploadTitle = Purchase Order Validator
...
# Delegate to the ecommerce validator
validator.domainAlias = ecommerce
validator.domainAlias.basic.v1.1.0 = order_basic.v1.1.0
validator.domainAlias.basic.v1.0.0 = order_basic.v1.0.0
validator.domainAlias.large.v1.1.0 = order_large.v1.1.0
validator.domainAlias.large.v1.0.0 = order_large.v1.0.0
Similarly, the invoice domain’s configuration is extended as follows:
validator.uploadTitle = Invoice Validator
...
# Delegate to the ecommerce validator
validator.domainAlias = ecommerce
validator.domainAlias.full = invoice_full
validator.domainAlias.summary = invoice_summary
These alias definitions, ensure that any requests to the legacy validators will be delegated transparently to the new
consolidated domain. Revisiting the validator’s filesystem resources, the order, invoice and ecommerce domains
are defined as follows:
validator
└── resources
├── order
│ ├── schemas
│ │ ├── PurchaseOrder_v1.1.0.json
│ │ └── PurchaseOrder_v1.0.0.json
│ └── config.properties
├── invoice
│ ├── schemas
│ │ └── Invoice.json
│ └── config.properties
└── ecommerce
├── order
│ └── schemas
│ ├── PurchaseOrder_v1.1.0.json
│ └── PurchaseOrder_v1.0.0.json
├── invoice
│ └── schemas
│ └── Invoice.json
└── config.properties
If your validator is self-hosted, this is would be the updated resource root folder you would provide as its configuration. Alternatively, if your validators are hosted by the Interoperability Test Bed, you likely have separate repositories for each configuration. This is not an issue however, as all you need to do is ensure each domain is set up correctly and the alias definitions are in place.
Note
Domain aliases work when all domains are defined in the same validator application. If this is not the case, you will need another solution such as reverse proxy rewriting and/or redirects. As this approach is outside the control of validators they are outside the scope of this guide.
Adding a custom banner and footer
The validator foresees configuration properties to further customise the validator’s web user interface by adding a rich banner and/or footer. Adding at least a banner to your validator goes a long way in making it more user friendly, providing needed context, but also references to supporting resources and support details.
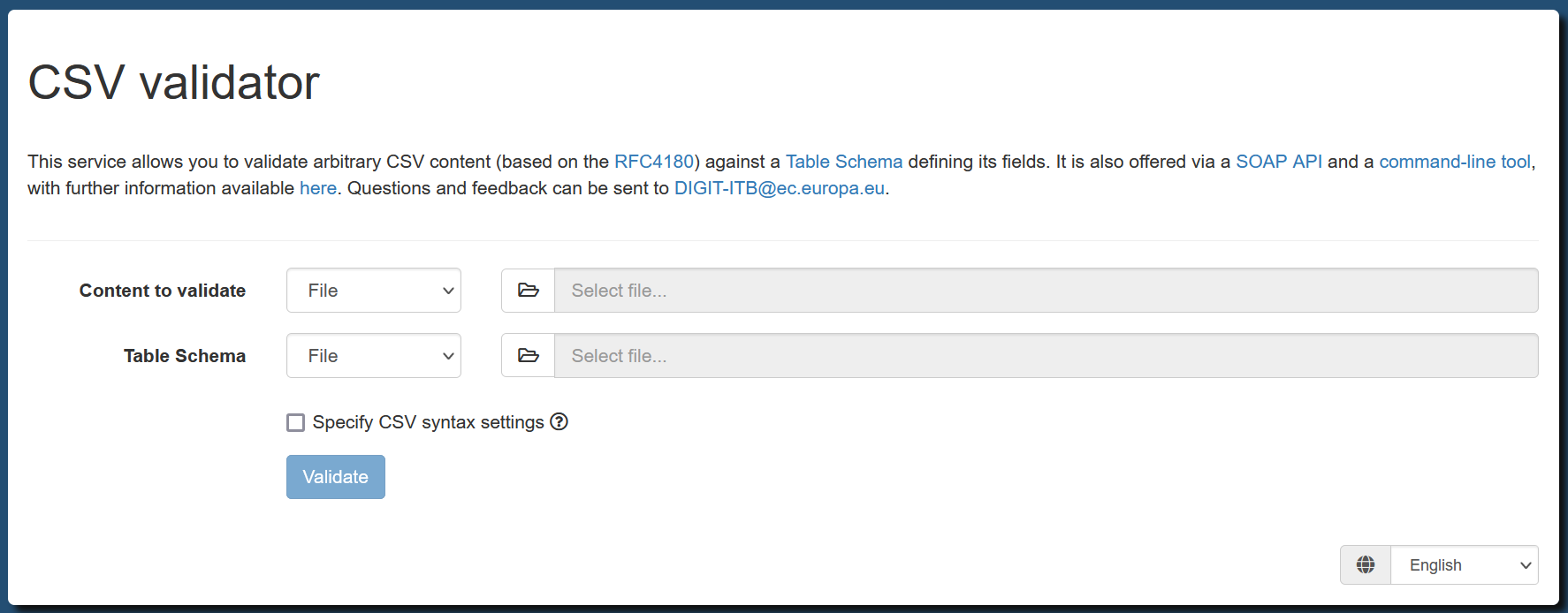
A good example of a simple banner can be drawn from the Test Bed’s generic CSV validator where apart from explaining the purpose of the validator, users are also informed of its alternate APIs and contact information.
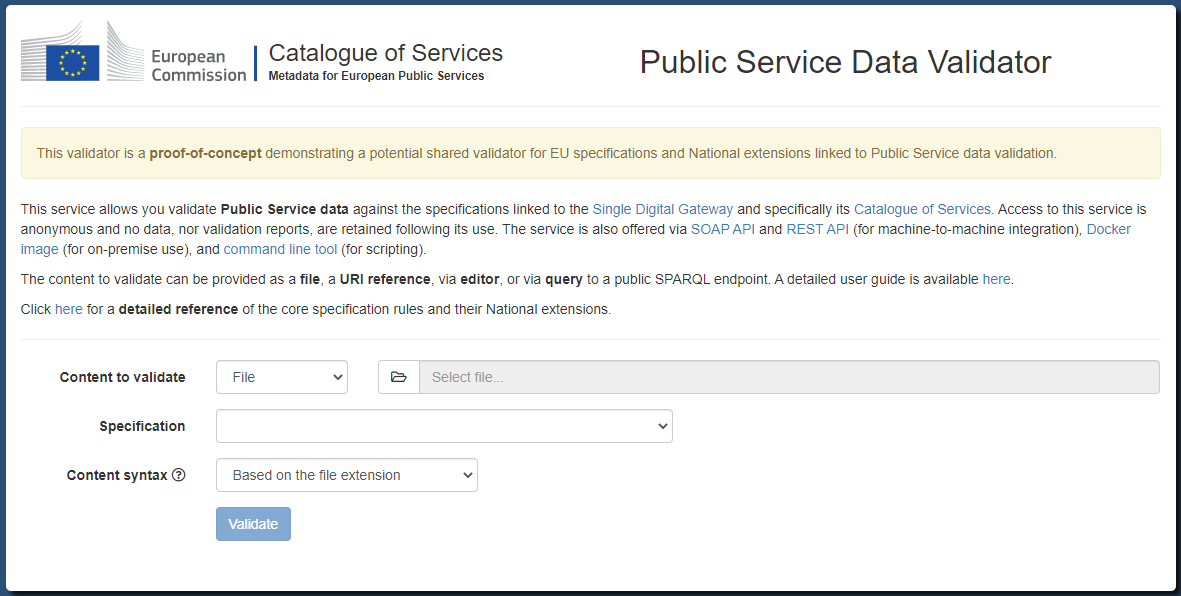
Banners can nonetheless be as complex as needed by introducing more advanced layouts, styling, and images, to provide further information and theming. A good example of such a banner is from the Public Service Data validator, a demo instance of the Test Bed’s RDF validator that includes images, text formatting, and popups (upon clicking provided links).
Adding a banner and footer to your validator is achieved by setting, respectively, the domain configuration properties
validator.bannerHtml and validator.footerHtml with a snippet of minified HTML code. This can also include CSS potentially
also making use of Bootstrap styles and components (version 3.*) that come already packaged in the validator. In
case you need to include JavaScript, you can add this in minified form through the separate validator.javascriptExtension property. In such scripts
you may also use JQuery.
Note
Banners and footers are only available for the validator’s normal user interface. If enabled, the validator’s minimal interface hides banners and footers to provide a more concise presentation.
A common approach to customise and test a new HTML snippet is to draft its general structure, run it on a browser, and use the browser’s developer
tools to fine-tune it. Once it suits your needs, the snippet is then minified (e.g. using any of the various online utilities for HTML and JavaScript),
before being set to the corresponding domain property (validator.bannerHtml, validator.footerHtml or validator.javascriptExtension).
As an example case, but also as a good starting point for your own banner, we can consider the banner configured for the generic CSV validator. The banner’s (pretty-printed) HTML snippet is the following:
<div>
<div style="display: table;">
<div style="display: table-row;">
<div style="display: table-cell; cursor: pointer;" class="validatorReload">
<h1>CSV validator</h1>
</div>
</div>
<div style="display: table-row;">
<div style="display: table-cell; padding-top: 20px;">
<p> This service allows you to validate arbitrary CSV content (based on the <a href="https://tools.ietf.org/html/rfc4180">RFC4180</a>) against a <a href="https://specs.frictionlessdata.io/table-schema/">Table Schema</a> defining its fields. It is also offered via a <a href="https://www.itb.ec.europa.eu/csv/soap/any/validation?wsdl">SOAP API</a> and a <a href="https://www.itb.ec.europa.eu/csv-offline/any/validator.zip">command-line tool</a>, with further information available <a href="https://www.itb.ec.europa.eu/docs/guides/latest/validatingCSV/">here</a>. Questions and feedback can be sent to <a href="mailto:DIGIT-ITB@ec.europa.eu">DIGIT-ITB@ec.europa.eu</a>. </p>
</div>
</div>
</div>
<hr>
</div>
The “validatorReload” class above is a marker class to allow us to attach basic JavaScript behaviour to reload the page on click. This is achieved by this script:
$(document).ready(function() {
$(".validatorReload").off().on("click", function() { window.location.href="upload"; });
});
Taking these snippets we can then minify them, to produce single line versions ready to set
in properties validator.bannerHtml and validator.javascriptExtension as follows:
...
validator.bannerHtml=<div><div style="display:table"><div style="display:table-row"><div style="display:table-cell;cursor:pointer" class="validatorReload"><h1>CSV validator</h1></div></div><div style="display:table-row"><div style="display:table-cell;padding-top:20px"><p>This service allows you to validate arbitrary CSV content (based on the<a href="https://tools.ietf.org/html/rfc4180">RFC4180</a>) against a<a href="https://specs.frictionlessdata.io/table-schema/">Table Schema</a>defining its fields. It is also offered via a<a href="https://www.itb.ec.europa.eu/csv/soap/any/validation?wsdl">SOAP API</a>and a<a href="https://www.itb.ec.europa.eu/csv-offline/any/validator.zip">command-line tool</a>, with further information available<a href="https://www.itb.ec.europa.eu/docs/guides/latest/validatingCSV/">here</a>. Questions and feedback can be sent to<a href="mailto:DIGIT-ITB@ec.europa.eu">DIGIT-ITB@ec.europa.eu</a>.</p></div></div></div><hr></div>
validator.javascriptExtension=$(document).ready(function() { $(".validatorReload").off().on("click", function() { window.location.href="upload"; });});
Note
Use of CSS and images: For simple content the easiest approach is to define it inline within your HTML. For images it is best to add them as remote references, although for very small ones you may also define them inline as data URLs. Keep in mind however to try and keep the content’s size small as such inline content is not browser-cacheable.
Supporting multiple languages
Certain configuration properties we have seen up to now define texts that are visible to the validator’s users. Examples of these include the title of
the validator’s user interface (validator.uploadTitle) or the labels to present for the available validation types (validator.typeLabel.TYPE),
which in the sample configuration are set with English values. Depending on your validator’s audience you
may want to switch to a different language or support several languages at the same time. Supporting multiple languages affects:
The texts, labels and messages presented on the validator’s user interface.
The reports produced after validating content via any of the validator’s interfaces.
The text values used by default by the validator are defined in English (see default values here), with English being the language considered by the validator if no other is selected. If your validator needs to support only a single language, a simple approach is to ensure that the domain-level configuration properties for texts presented to users are defined in the domain configuration file with the values for your selected language. Note that as long as the validator’s target language is an EU official language you need not provide translations for user interface labels and messages as these are defined by the validator itself. You are nonetheless free to redefine these to override the defaults or to define them for a non-supported language.
In case you want your validator to support multiple languages at the same time you need to adapt your configuration to define the supported languages and their specific translations. To do this adapt your domain configuration property file making use of the following properties:
validator.locale.available: The list of languages to be supported by the validator, provided as a comma-separated list of language codes (locales). The order these are defined with determines their presentation order in the validator’s user interface.
validator.locale.default: The validator’s default language, considered if no specific language has been requested. If multiple languages are supported the default needs to be set to one of these.
validator.locale.translations: The path to a folder (absolute or relative to the domain configuration file) that contains the translation property files for the validator’s supported languages.
Each language (locale) is defined as a 2-character lowercase language code (based on ISO 639), followed by an optional 2-character uppercase country code (based on ISO 3166)
separated using an underscore character (_). The format is in fact identical to that used to define locales in the Java language. Valid examples include “fr” for French,
“fr_FR” for French in France, or “fr_BE” for French in Belgium. Such language codes are the values expected to be used for properties validator.locale.available and
validator.locale.default.
Regarding property validator.locale.translations, the value is expected to be a folder containing the translation files for your selected languages. These are defined
exactly as you would define a resource bundle in a Java program, specifically:
The names of all property files start with the same prefix. Any value can be selected with good examples being “labels” or “translations”.
The common prefix is followed by the relevant locale value (language code and country code) separated with an underscore.
The files’ extension is set as “.properties”.
Considering the above, good examples of translation property file names would be “labels_de.properties”, “labels_fr.properties” and “labels_fr_FR.properties”. Note that these files are implicitly hierarchical meaning that for related locales you need not redefine all properties. For example you may have your French texts defined in “labels_fr.properties” and only override what you need in “labels_fr_BE.properties”. You can also define an overall default translation file by omitting the locale in its name (labels.properties) which will be used when no locale-specific file exists or if it exists but does not include the given property key. Note additionally that if you define translatable text values in your main domain configuration file these are considered as overall defaults if no specific translations could be found in translation files.
In terms of contents, the translation files are simple property files including key-value pairs. Each such pair defines as its key the property key for the given text, with the value being the translation to use. The properties that can be defined in such files are:
Any domain-level configuration properties that are marked as being a translatable String.
Any user interface labels and messages if you want to override the default translations.
Considering that you typically wouldn’t need to override labels and messages, the texts you would need to translate are the ones relevant to your specification. These are most often the following:
The title of the validator’s UI (
validator.uploadTitle).The UI’s HTML banner content (
validator.bannerHtml), which can be customised as explained in Adding a custom banner and footer.The descriptions for the validation types that you define and their options (
validator.typeLabel.TYPE,validator.optionLabel.OPTION,validator.typeOptionLabel.TYPE.OPTIONandvalidator.completeTypeOptionLabel.TYPE.OPTION).
To illustrate how all this comes together let’s revisit our Purchase Order example. In our current, single-language and English-only setup, the configuration files are structured as follows:
validator
└── resources
└── order
├── schemas
│ ├── PurchaseOrder.schema.json
│ └── PurchaseOrder-large.schema.json
└── config.properties
The domain configuration file (config.properties) defines itself the user-presented texts (see highlighted lines):
validator.type = basic, large
validator.typeLabel.basic = Basic purchase orders
validator.typeLabel.large = Large purchase orders
validator.schemaFile.basic = schemas/PurchaseOrder.schema.json
validator.schemaFile.large = schemas/PurchaseOrder-large.schema.json
validator.uploadTitle = Purchase Order Validator
Starting from this point we will make the necessary changes to support alongside English (which remains the default language), German and French translations. The first
step is to adapt the config.properties file to remove the contained translations. We could have kept these here for English but as we will be adding specific translation
files it is cleaner to move all translations to them. The content of config.properties becomes now as follows:
validator.type = basic, large
validator.schemaFile.basic = schemas/PurchaseOrder.schema.json
validator.schemaFile.large = schemas/PurchaseOrder-large.schema.json
validator.locale.available = en,fr,de
validator.locale.default = en
validator.locale.translations = translations
To define the translations we will introduce a new folder translations (as defined in property validator.locale.translations) that includes the property files per locale:
validator
└── resources
└── order
├── schemas
│ ├── PurchaseOrder.schema.json
│ └── PurchaseOrder-large.schema.json
├── translations
│ ├── labels_en.properties
│ ├── labels_fr.properties
│ └── labels_de.properties
└── config.properties
The English translations are provided in labels_en.properties (these are simply moved here from the config.properties file):
validator.typeLabel.basic = Basic purchase order
validator.typeLabel.large = Large purchase order
validator.uploadTitle = Purchase Order Validator
French translations are defined in labels_fr.properties:
validator.typeLabel.basic = Bon de commande de base
validator.typeLabel.large = Bon de commande important
validator.uploadTitle = Validateur de bon de commande
And finally German translations are defined in labels_de.properties:
validator.typeLabel.basic = Grundbestellung
validator.typeLabel.large = Großbestellung
validator.uploadTitle = Bestellbestätigung
This completes the validator’s localisation configuration. With this setup in place, the user will be able to select one of the supported languages to change the validator’s user interface and resulting report. Note that localised reports can also now be produced from the validator’s REST API, SOAP API and command-line tool.
Validation metadata in reports
The machine-processable report produced when calling the validator via its SOAP API, REST API, or downloaded from its user interface, uses the GITB Test Reporting Language (TRL). The GITB TRL is an XML format, but when using the REST API in particular, it may also be generated in JSON.
Apart from defining the report’s main content, the GITB TRL format foresees optional metadata to provide information on the validation service itself and the type of validation applied. Specifically:
An identifier and name for the report.
A name and version for the validator.
The validation profile considered as well as any type-specific customisation.
The inclusion of all such properties is driven through your domain configuration file. The report and validator metadata are optional fixed values that you may configure to apply to all produced reports. The validation profile and its customisation however, apart from also supporting overall default values, can furthermore be set with values depending on configured validation types. If nothing is configured, the only metadata included by default is the profile, that is set to the validation type that was considered to carry out the validation (selected by the user, or implicit if there is a single defined type or a default).
The following table summarises the available report metadata, the relevant configuration properties and their configuration approach:
Report element |
Configuration property |
Description |
|---|---|---|
|
|
Identifier for the overall report, set as a string value. |
|
|
Name for the overall report, set as a string value. |
|
|
Name for the validator, set as a string value. |
|
|
Version for the validator, set as a string value. |
|
|
The applied profile (validation type). Multiple entries can be added for configured validation types added as a postfix. When defined without a postfix the value is considered as an overall default. If entirely missing this is set to the applied validation type. |
|
|
A customisation of the applied profile. Multiple entries can be added for configured validation types added as a postfix. When defined without a postfix the value is considered as an overall default. |
To illustrate the above properties consider first the following XML report metadata, produced by default if no relevant configuration is provided. Only the profile is included, set to the validation type that was used:
<TestStepReport>
...
<overview>
<profileID>basic</profileID>
</overview>
...
</TestStepReport>
Extending now our domain configuration, we can include additional metadata as follows:
# A name to display for the validator.
validator.report.validationServiceName=Purchase Order Validator
# A version to display for the validator.
validator.report.validationServiceVersion=v1.0.0
# The name for the overall report.
validator.report.name=Purchase order validation report
# The profile to display depending on the selected validation type (basic or large).
validator.report.profileId.basic=Basic purchase order
validator.report.profileId.large=Large purchase order
Applying the above configuration will result in GITB TRL reports produced with the following metadata included:
<TestStepReport name="Purchase order validation report">
...
<overview>
<profileID>basic</profileID>
<validationServiceName>Purchase Order Validator</validationServiceName>
<validationServiceVersion>v1.0.0</validationServiceVersion>
</overview>
...
</TestStepReport>
In a JSON report produced by the validator’s REST API the metadata would be included as follows:
{
...
"overview": {
"profileID": "Basic purchase order",
"validationServiceName": "Purchase Order Validator",
"validationServiceVersion": "v1.0.0"
},
...
"name": "Purchase order validation report"
}
Rich text support in report items
A validation report’s items represent the findings of a given validation run. The description of report items is by default treated as simple text and displayed as such in all report outputs. If this description includes rich text (i.e. HTML) content, the validator’s user interface will escape and display it as-is without rendering it.
It is possible to configure your validator to expect report items with descriptions including rich text, and specifically HTML links (anchor elements). If enabled, links will be rendered as such in the validator’s user interface and PDF reports, so that when clicked, their target is opened in a separate window. A typical use case for this would be to link each reported finding with online documentation that provides further information or a normative reference.
To enable HTML links in report items set property validator.richTextReports to true as part of your
domain configuration properties.
validator.richTextReports = true
It is important to note that with this feature enabled, the description of report items is sanitised to remove any rich content that is not specifically a link. If found, non-link HTML tags are stripped from descriptions, leaving only their contained text (if present).
Adding custom text to PDF reports
When you choose to produce a PDF report, the validator will generate a report that includes:
The name of the file that was validated.
The type of validation that was performed.
The validation date and result.
A summary of the resulting findings and the detailed list of reports.
To further customize this report you can define custom text blocks that will be included in specific sections, notably:
Before the overview section (acting also as a banner for the report).
As the first content in each report finding section (for errors, warnings and messages).
These texts can be defined as HTML, including text formatting, styling and links. This allows you to provide potentially elaborate content that can customise reports for your validator’s audience. In addition, you can define different blocks to include depending on the result of the validation and even the selected validation type.
Custom text blocks can be included by means of the following configuration properties:
validator.customReportMessage.overviewSection, for the overview section.validator.customReportMessage.errorsSection, for the section listing errors.validator.customReportMessage.errorsSection, for the section listing warnings.validator.customReportMessage.errorsSection, for the section listing information messages.
Multiple such properties can be defined, by adding a success or failure postfix to display different text blocks
depending on the validation result. In addition, the full validation type (validation type plus option) can be further
post-fixed to add variants for specific validation types.
The following example shows how you could extend your PDF reports with a “failure” banner that provides instructions on next steps:
# Add a message before the overview section to appear in case of a failure.
# Use inline styles to define an appealing error message.
validator.customReportMessage.overviewSection.failure = <div style="border: 1px solid #cc3d39; border-radius: 5px; padding: 10px; margin-bottom: 10px; background: #f2dede">Validation against the <a href="https://github.com/myProject">project rules</a> <b>failed</b>. Please consult the report's findings to determine the issues and take corrective actions.</div>
# Add a specific error message in case the 'large' validation type was selected.
validator.customReportMessage.overviewSection.failure.large = <div style="border: 1px solid #cc3d39; border-radius: 5px; padding: 10px; margin-bottom: 10px; background: #f2dede">Note that the large specs are currently shared in beta mode..</div>
Note
HTML content limitations: Only text formatting, blocks, links and basic inline styles are supported. Any additional HTML you add will be stripped before being included in reports.
Step 4: Setup validator as Docker container
Note
When to setup a Docker container: The purpose of setting up your validator as a Docker container is to host it yourself or run it locally on workstations. If you prefer or don’t mind the validator being accessible over the Internet it is simpler to delegate hosting to the Test Bed team by reusing the Test Bed’s infrastructure. If this is the case skip this section and go directly to Step 5: Setup validator on Test Bed. Note however that even if you opt for a validator managed by the Test Bed, it may still be interesting to create a Docker image for development purposes (e.g. to test new validation artefact versions) or to make available to your users as a complementary service (i.e. use online or download and run locally).
Once the validator’s configuration is ready (configuration file and validation artefacts) you can proceed to create a Docker image.
The configuration for your image is driven by means of a Dockerfile. Create this file in the validator folder with the following
contents:
FROM isaitb/csv-validator:latest
COPY resources /validator/resources/
ENV validator.resourceRoot /validator/resources/
This Dockerfile represents the most simple Docker configuration you can provide for the validator. Let’s analyse each line:
|
This tells Docker that your image will be built over the latest version of the Test Bed’s |
|
This copies your |
|
This instructs the validator that it should consider as the root of all its configuration resources the |
The contents of the validator folder should now be as follows:
validator
├── resources
│ └── order
│ ├── shapes
│ │ ├── PurchaseOrder.schema.json
│ │ └── PurchaseOrder-large.schema.json
│ └── config.properties
└── Dockerfile
That’s it. To build the Docker image open a command prompt to the validator folder and issue:
docker build -t po-validator .
This command will create a new local Docker image named po-validator based on the Dockerfile it finds in the current directory.
It will proceed to download missing images (e.g. the isaitb/csv-validator:latest image) and eventually print the following
output:
Sending build context to Docker daemon 32.77kB
Step 1/3 : FROM isaitb/csv-validator:latest
---> 39ccf8d64a50
Step 2/3 : COPY resources /validator/resources/
---> 66b718872b8e
Step 3/3 : ENV validator.resourceRoot /validator/resources/
---> Running in d80d38531e11
Removing intermediate container d80d38531e11
---> 175eebf4f59c
Successfully built 175eebf4f59c
Successfully tagged po-validator:latest
The new po-validator:latest image can now be pushed to a local Docker registry or to the Docker Hub. In our case we will proceed
directly to run this as follows:
docker run -d --name po-validator -p 8080:8080 po-validator:latest
This command will create a new container named po-validator based on the po-validator:latest image you just built. It is set
to run in the background (-d) and expose its internal listen port through the Docker machine (-p 8080:8080). Note that by default
the listen port of the container (which you can map to any available host port) is 8080.
Your validator is now online and ready to validate CSV content. If you want to try it out immediately skip to Step 6: Use the validator. Otherwise, read on to see additional configuration options for the image.
Running without a custom Docker image
The discussed approach involved building a custom Docker image for your validator. Doing so allows you to run the validator yourself but also potentially push it to a public registry such as the Docker Hub. This would then allow anyone else to pull it and run a self-contained copy of your validator.
If such a use case is not important for you, or if you want to only use Docker for your local artefact development, you could also skip
creating a custom image and use the base isaitb/csv-validator image directly. To do so you would need to:
Define a named or unnamed Docker volume pointing to your configuration files.
Run your container by configuring it with the volume.
Considering the same file structure of the /validator folder you can launch your validator using an unnamed volume as follows:
docker run -d --name po-validator -p 8080:8080 \
-v /validator/resources:/validator/resources/ \
-e validator.resourceRoot=/validator/resources/ \
isaitb/csv-validator
As you see here we create the validator directly from the base image and pass it as a volume our resource root folder. When doing so you need to also make sure
that the validator.resourceRoot environment variable is set to the path within the container.
Using this approach to run your validator has the drawback of being unable to share it as-is with other users. The benefit however is one of simplicity given that there is no need to build intermediate images. As such, updating the validator for configuration changes means that you only need to restart your container.
Note
Running the default docker image can also be done without providing a validator.resourceRoot. If you decide to do this, a generic instance with the any validator
will automatically be set-up for you and you will be able to access it on http://localhost:8080/csv/any/upload.
Configuring additional validation domains
Up to this point you have configured validation for purchase orders which defines one or more validation types (basic and large).
This configuration can be extended by providing additional types to reflect:
Additional profiles with different business rules (e.g.
minimal).Specification versions (e.g.
basic_v1.0,large_v1.0,basic_v1.1_beta).Other types of content that are linked to purchase orders (e.g.
purchase_order_basic_v1.0andorder_receipt_v1.0).
All such extensions would involve defining potentially additional validation artefacts and updating the config.properties file
accordingly.
Apart from extending the validation possibilities linked to purchase orders you may want to configure a completely separate validator to address an unrelated specification that would most likely not be aimed to the same user community. To do so you have two options:
Repeat the previous steps to define a separate configuration and a separate Docker image. In this case you would be running two separate containers that are fully independent.
Reuse your existing validator instance to define a new validation domain. The result will be two validation services that are logically separate but are running as part of a single validator instance.
The rationale behind the second option is simply one of required resources. If you are part of an organisation that needs to support validation for dozens of different types of CSV content that are unrelated, it would probably be preferable to have a single application to host rather than one per specification.
Note
Sharing artefact files accross domains: Setting the application property validator.restrictResourcesToDomain to false allows to
add paths of validation artefacts that are outside of the domain root folder. This enables sharing artefacts between different domains.
In your current single domain setup, the purchase order configuration is reflected through folder order. The name of this folder
is also by default assumed to match the name of the domain. A new domain could be named invoice that is linked to CSV invoices.
This is represented by an invoice folder next to order that contains similarly its validation artefacts and domain-level
configuration property file. Considering this new domain, the contents of the validator folder would be as follows:
validator
├── resources
│ ├── invoice
│ │ └── (Further contents skipped)
│ └── order
│ └── (Further contents skipped)
└── Dockerfile
If you were now to rebuild the validator’s Docker image this would setup two logically-separate validation domains (invoice and
order).
Note
Validation domains vs types: In almost all scenarios you should be able to address your validation needs by having a single validation domain with multiple validation types. Validation types under the same domain will all be presented as options for users. Splitting in domains would make sense if you don’t want the users of one domain to see the supported validation types of other domains.
Important: Support for such configuration is only possible if you are defining your own validator as a Docker image. If you plan to use the Test Bed’s shared validator instance (see Step 5: Setup validator on Test Bed), your configuration needs to be limited to a single domain. Note of course that if you need additional domains you can in this case simply repeat the configuration process multiple times.
Additional configuration options
We have seen up to now that configuring how validation takes place is achieved through domain-level configuration properties
provided in the domain configuration file (file config.properties in our example). When setting up the validator as a
Docker image you may also make use of application-level configuration properties
to adapt the overall validator’s operation. Such configuration properties are provided as environment variables through ENV
directives in the Dockerfile.
We already saw this when defining the validator.resourceRoot property that is the only mandatory property for which no
default exists. Other such properties that you may choose to override are:
validator.domain: A comma-separated list of names that are to be loaded as the validator’s domains. By default the validator scans the providedvalidator.resourceRootfolder and selects as domains all subfolders that contain a configuration property file (folderorderin our case). You may want to configure the list of folder names to consider if you want to ensure that other folders get ignored.validator.domainName.DOMAIN: A mapping for a domain (replacing theDOMAINplaceholder) that defines the name that should be presented to users. This would be useful if the folder name itself (orderin our example) is not appropriate (e.g. if the folder was namedfiles).validator.rateLimit.*: A series of properties that allow you to configure validation rate limits per client IP address and requested endpoint.
The following example Dockerfile illustrates use of these properties. The values set correspond to the applied defaults so the resulting Docker images from this Dockerfile and the original one (see Step 4: Setup validator as Docker container) are in fact identical:
FROM isaitb/csv-validator:latest
COPY resources /validator/resources/
ENV validator.resourceRoot /validator/resources/
ENV validator.domain order
ENV validator.domainName.order order
In case you want to configure validation rate limits for your validator (per validator instance), the following configuration shows an example setup:
# Enable validation rate limits (by default no limits are enforced).
ENV validator.rateLimit.enabled true
# When a limit is exceeded return a 429 "Too Many Requests" response (including a Retry-After header).
ENV validator.rateLimit.warnOnly false
# Read the client's IP address from the X-Real-IP (in case the validator is proxied).
ENV validator.rateLimit.ipHeader X-Real-IP
# Apply limits per minute of 100 for the UI, 500 for the REST API, 50 for the bulk REST API, and 400 for the SOAP API.
ENV validator.rateLimit.capacity.uiValidate 100
ENV validator.rateLimit.capacity.restValidate 500
ENV validator.rateLimit.capacity.restValidateMultiple 50
ENV validator.rateLimit.capacity.soapValidate 400
See Application-level configuration for the full list of supported application-level properties.
Finally, it may be the case that you need to adapt further configuration properties that relate to how the validator’s
application is ran. The validator is built as a Spring Boot application which means that you can override all
configuration properties by means of environment variables. This is rarely needed as you can achieve most important
configuration through the way you run the Docker container (e.g. defining port mappings). Nonetheless the following
adapted Dockerfile shows how you could ensure the validator’s application starts up on another port (9090) and
uses a specific context path (/ctx).
FROM isaitb/csv-validator:latest
COPY resources /validator/resources/
ENV validator.resourceRoot /validator/resources/
ENV server.servlet.context-path /ctx
ENV server.port 9090
Note
Custom port: Even if you define the server.port property to a different value other than the default 8080
this remains internal to the Docker container. The port through which you access the validator will be the one you
map on your host through the -p flag of the docker run command.
The full list of such application configuration properties, as well as their default values, are listed in the Spring Boot configuration property documentation.
Environment-specific domain configuration
In the previous section you saw how could can configure the validator’s application by means of environment properties. Use of environment properties is also possible for specific validator domains, allowing you to externalise and override their configuration aspects. Typical cases where you may want to do this are:
To adapt the configuration for different instances of the same validator.
To hide sensitive properties such as internal URLs or passwords.
External configuration properties can be provided through environment variables or system properties (the latter being interesting when using a command line validator). These can contribute to the configuration:
Complete properties, by defining a variable or property with the same name as a configuration property.
Values, by referring to arbitrary variables or properties within a domain property file. This is done by defining a placeholder
${}and using within it the prefixesenv:for environment variables orsys:for system properties (e.g.${env:MY_VARIABLE}).
As a simple example of this, consider the definition of the title of the validator’s web UI. We want to adapt this title
depending on the purpose of the specific validator instance. To begin with we can define the title via the validator.uploadTitle
property in the config.properties file as follows:
validator.uploadTitle = Purchase Order Validator
The problem with this approach is that the upload title remains fixed across all instances of the validator. Alternatively
we can define the value for the title as an environment variable named VALIDATOR_TITLE. To use this we can adapt
config.properties to reference it as follows:
validator.uploadTitle = ${env:VALIDATOR_TITLE}
We can then adapt this for each Docker container we create by defining a specific value for the title:
docker run -e VALIDATOR_TITLE="Purchase Order Validator (Demo)" ...
A further alternative would be to externalise the complete validator.uploadTitle property by removing it from
config.properties and specifying it as an environment variable:
docker run -e validator.uploadTitle="Purchase Order Validator (Demo)" ...
Note that such external configuration can also be used as a partial value. If we define an environment variable named
VALIDATOR_ENV we could also use it within config.properties as follows:
validator.uploadTitle = Purchase Order Validator (${env:VALIDATOR_ENV})
Finally, you can use environment or system variables to override properties that are already defined in config.properties.
This is useful if you use the file’s properties as default values and selectively override certain of them as needed. A
property’s value is looked up in sequence as follows:
Look in environment variables.
If not found look in system properties.
If not found look in the domain configuration file.
If not found consider the property’s overall default value (see Domain-level configuration).
Step 5: Setup validator on Test Bed
Note
When to setup on Test Bed resources: Setting up your validator on the Test Bed’s resources removes hosting concerns and allows you to benefit from automatic service reloads for configuration changes. In doing so however you need to keep in mind that the validator will be exposed over the Internet. If this approach is not suitable for you (e.g. you want to expose the validator within a restricted network) you should consider setting up the validator as a Docker container (see Step 4: Setup validator as Docker container) that you can then host as you see fit.
To configure a validator using the Test Bed’s resources all you need to do is get in touch with the Test Bed team and provide the validator’s configuration. Specifically:
Send an email to DIGIT-ITB@ec.europa.eu describing your case: This step is needed for two reasons. Firstly you may want to have a further discussion and potentially a demo to better understand the available options. Secondly the Test Bed’s team would need to ensure that you qualify to use its resources (to e.g. avoid that you are a private company planning to offer commercial validation services).
Share the configuration for the validator: Once contact has been established you need to provide the initial configuration for the validator.
Regarding the second step, the validator’s configuration to be shared is the contents of the validator folder as described in Step 3: Prepare validator configuration.
The eventual goal here will be to have the configuration available through an accessible Git repository. This can be done in a number of
ways listed below in decreasing order of preference:
Create a new Git repository: You can push all resources (the
validatorfolder) to a new Git repository (e.g. on GitHub or the European Commission’s CITNet Bitbucket server). You can of course add any other resources to this repository as you see fit (e.g. a README file). Once done provide the repository’s URL to the Test Bed team.Provide the resources to the Test Bed team: You can send the configuration files themselves to the Test Bed’s team (e.g. make an archive of the
validatorfolder). Ideally you should define the configuration file but if in doubt you can simply describe the resources and the Test Bed team will prepare the initial configuration for you. When following this approach a new Git repository will be created for you on the European Commission’s CITNet Bitbucket server or on GitHub for which you will be assigned write access (assuming you have a relevant user account).Update an existing Git repository: If you already have a Git repository to maintain the validation artefacts you can reuse this by adding to it the required configuration file (
config.propertiesin our case). When ready you will need to provide the Test Bed team with the URL to the repository and the location of the configuration file.
Following the initial configuration, the resulting Git repository will be monitored to detect any changes to the validation artefacts or the configuration file. If such a change is detected, the validation service will be automatically updated within a few minutes.
Note
Using a dedicated Git repository for the validator: Whether you define a new Git repository yourself or the Test Bed team creates one for you, the result is a repository that is dedicated to the validator. This approach is preferable to reusing an existing Git repository to avoid unwanted changes to the validator. whether or not this is done through GitHub, CITNet’s Bitbucket or another service depends on what best suits your needs.
As part of the initial setup for the validator the Test Bed team will also configure how it is accessed. The name used will match the name
of the folder that contains your configuration file (order in the considered example), but this can differ according to your preferences.
If this is the case make sure to inform the Test Bed team of your preferred naming.
Considering our example, for a name of order, the resulting root URL through which the validator will be accessed is
https://www.itb.ec.europa.eu/csv/order. The specific paths will depend on the supported validation channels as described in Step 6: Use the validator.
Step 6: Use the validator
Well done! At this step your validator has been successfully configured and is ready to use. Depending on which approach was followed, this may have been done either:
As a Docker container (described in Step 4: Setup validator as Docker container).
Through the Test Bed’s resources (described in Step 5: Setup validator on Test Bed).
The validation channels that are supported depend on the configuration you have supplied. This is done through the validator.channels
property of your configuration file (config.properties) that defaults to form, rest_api, soap_api. The supported channels are as follows:
form: A web user interface allowing a user to provide the CSV content to validate.
rest_api: A REST API allowing machine-to-machine integration using HTTP calls.
soap_api: A SOAP API allowing contract-based machine-to-machine integration using SOAP web service calls.
The following sub-sections describe how each channel can be used considering the example EU purchase order specification.
Validation via user interface
The validator’s user interface is available at the /csv/DOMAIN/upload path. The exact path depends on how this is deployed:
Via Docker: http://DOCKER_MACHINE:8080/csv/order/upload
On the Test Bed: https://www.itb.ec.europa.eu/csv/order/upload
The first page that you see is a simple form to provide the CSV content to validate.
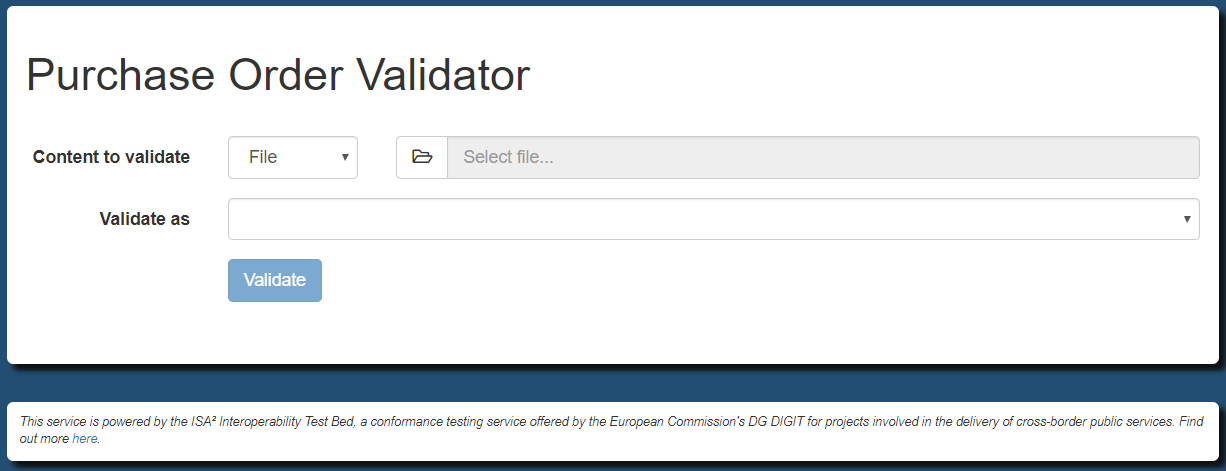
This form expects the following input:
Content to validate: The CSV content that will be submitted for validation. The preceding dropdown selection determines how this will be provided, specifically as a file input (pre-selected), as a URI to be loaded remotely or as content to be provided using an editor.
Validate as: The type of validation to apply.
The dropdown menu to the right of the Content to validate label selects the input method. For this you have three choices:
File: Content provided as a file upload (the default).
URI: Content provided as a remote URI reference.
Direct input: Content encoded directly in an on-screen editor.
Note
URI inputs: URI inputs ar disabled by default to prevent Server-Side Request Forgery (SSRF) attacks. You may
enable these at application-level (via property validator.allowUriInputs), and specifying a whitelist of
trusted base URIs (via property validator.allowedUriInputs).
In case the validator is configured to support multiple languages, the form includes an additional dropdown menu to list them in the bottom-right corner. Selecting one of these languages will reload the interface and will record your choice to apply it automatically for future visits.
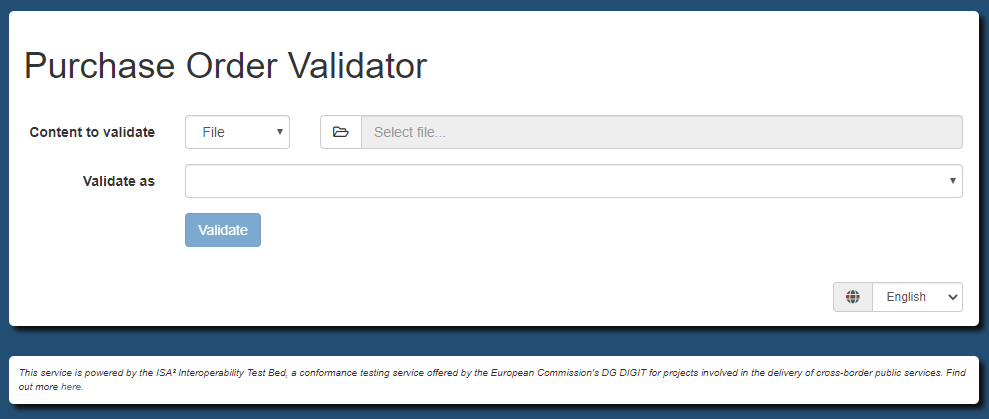
Note that all displayed labels can be adapted through the config.properties configuration file (see Properties related to UI labels).
The available validation types match the ones defined in the validator.type property, displayed using the validator.typeLabel.TYPE labels.
Moreover, the text title could be replaced by a configurable HTML banner, and further complemented with a HTML footer (see Domain-level configuration).
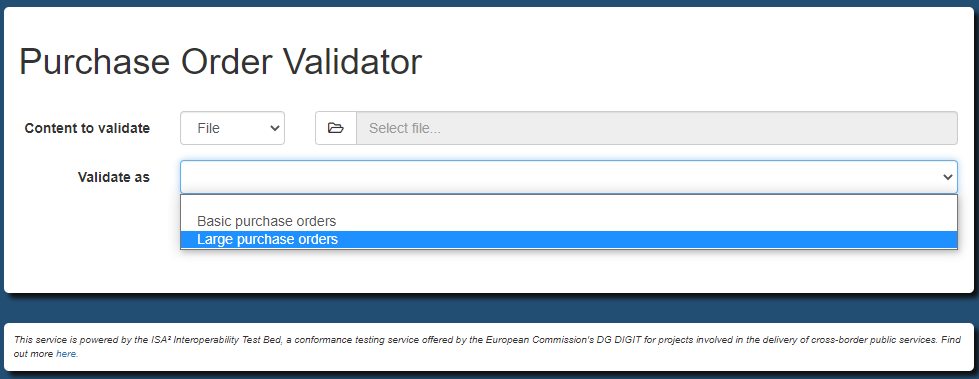
It is worth noting also that if your configuration defined only a single validation type, the user interface would be simplified by presenting only the content input controls (i.e. considering the single validation type as pre-selected).
In addition, if your configuration for the selected validation type allows for a user-provided schema, the form also includes the controls to manage this. The user-provided schema can be defined via file upload or remote URI and can be mandatory or optional depending on your configuration.
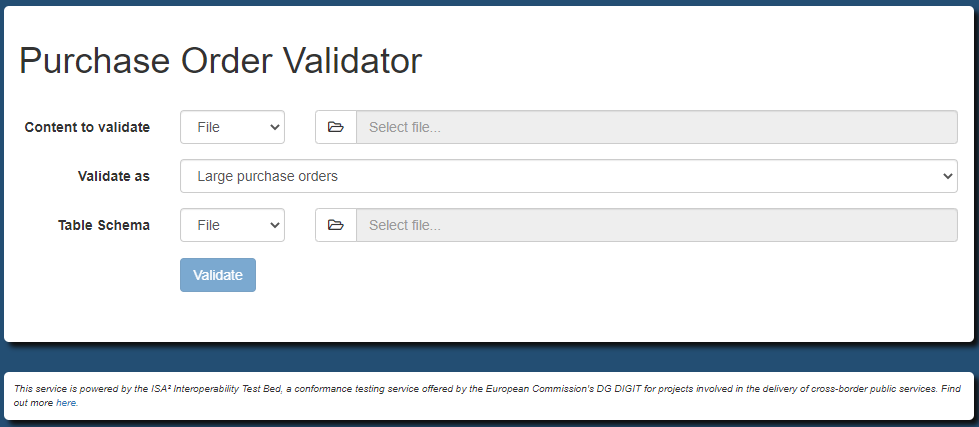
Finally, if you also specified in your configuration user inputs for syntax settings such as the presence of headers, delimiters and quotes, these will also be presented for input (either as optional or mandatory inputs).
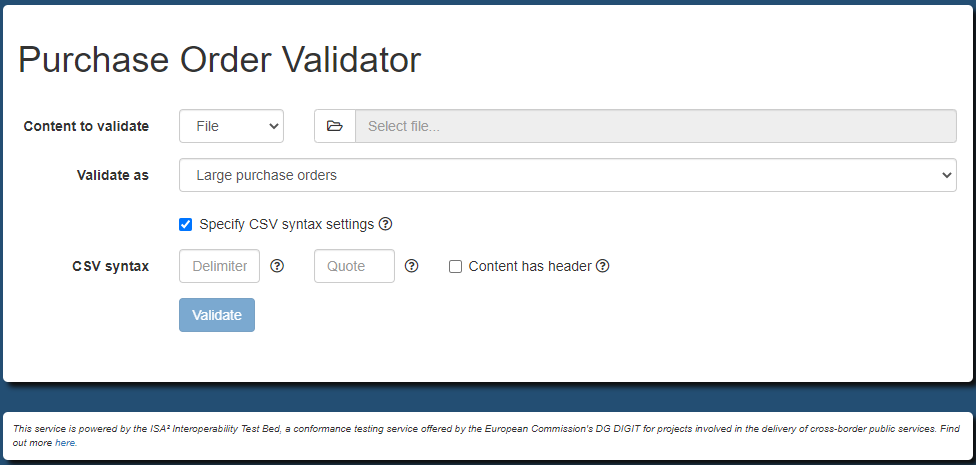
Once you have provided your input click the Validate button to trigger the validation. Upon completion you will be presented with the validation results:
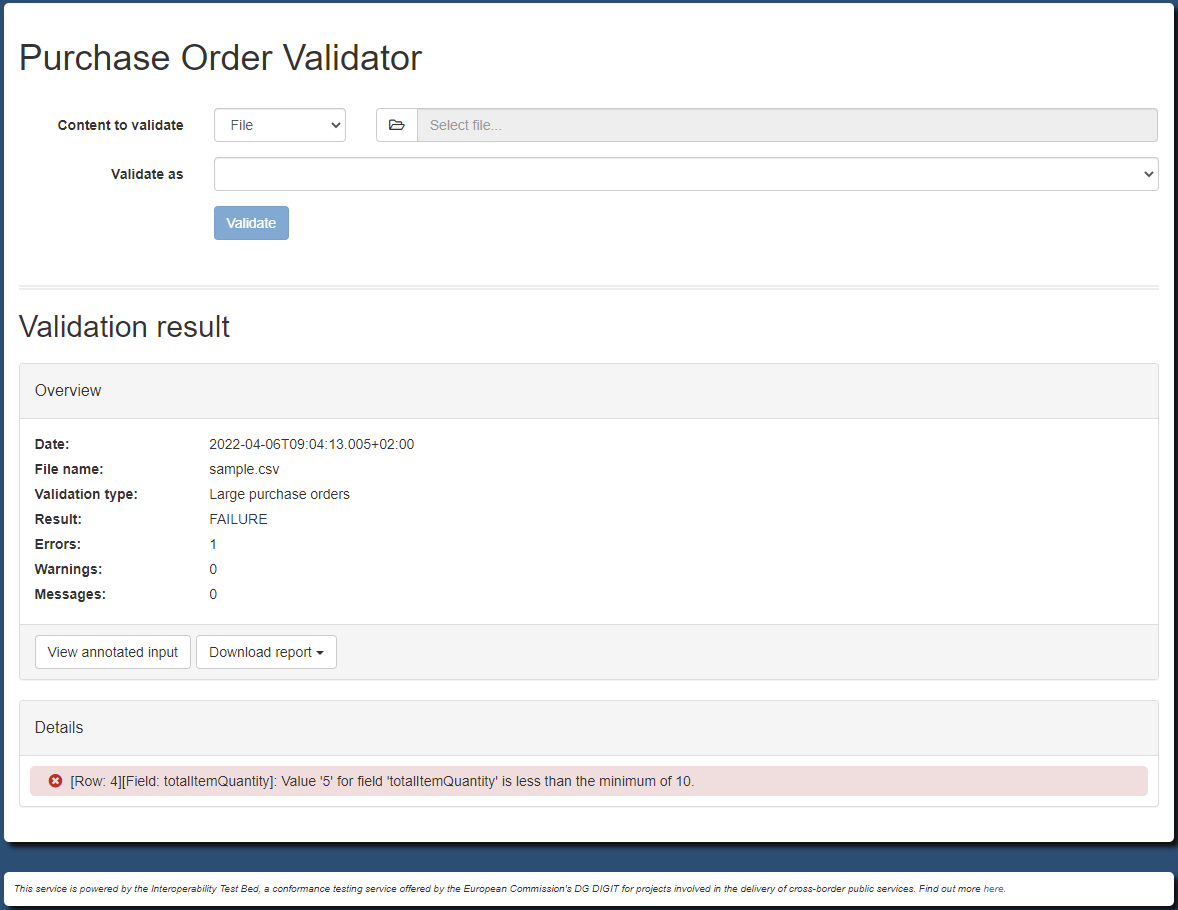
This screen includes an overview of the result listing:
The validation timestamp (in UTC), the name of the validated file and the applied validation type (if more than one are configured).
The overall result (
SUCCESSorFAILURE).The number of errors, warnings and information messages.
This section is followed by the Details panel, where the details of each report item are listed:
It’s type (whether this is an error, warning or information message).
It’s description.
Clicking on each item’s details will open a popup that shows within the provided content the specific point that triggered the issue:
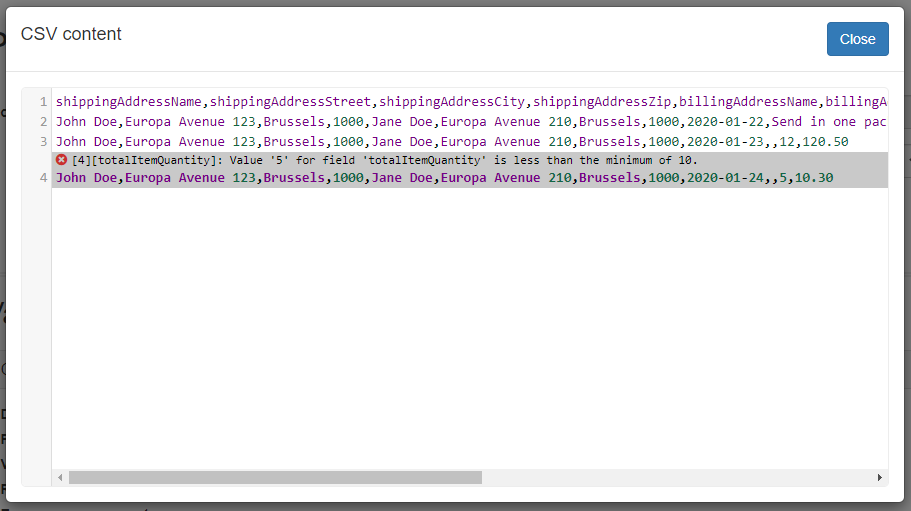
In terms or reporting, apart from the on-screen display, buttons are available allowing you to view the validation report:
Note that the download options are initially disabled but are enabled as soon as the respective reports become available.
In case validation has produced similar findings for multiple items, the validator offers the possibility to view reports in detailed (the default) or aggregated format. In case of an aggregated report, findings that relate to the same field and have the same description and severity, are merged to display only the first one, alongside an indication of the total number of occurrences. This indication is added as a prefix to the displayed description.
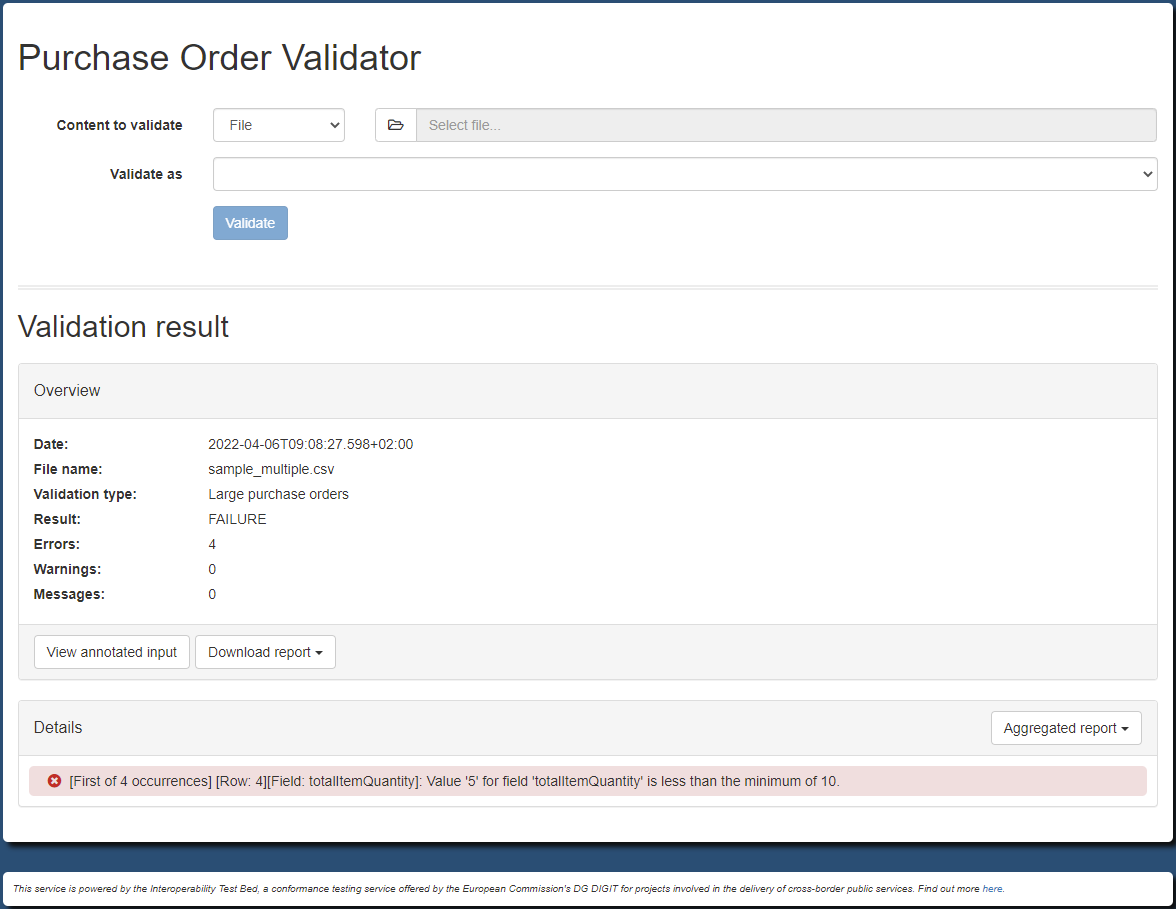
Aggregated reports are also available to download in XML, PDF or CSV formats. Regarding the on-screen display of findings, this can be switched between detailed and aggregated by using the provided control on the top of the “Details” panel. In case the validation report, detailed or aggregate, includes findings at different severity levels, you may also filter the displayed on-screen findings to show all items (the default), or show specifically errors, warnings and information messages.
Finally, once a validation result is produced you may trigger additional validations. To do this you may either use the form from the top of the result screen or click on the form’s title to take you back to the previous page.
Validation via minimal user interface
If you are exposing a web user interface (see Validation via user interface) for your validator you also have the option of enabling an alternative minimal interface that could be used
as an embedded component in another web page (e.g. via an iframe). This is enabled through the validator.supportMinimalUserInterface property
in your domain configuration (file config.properties).
...
validator.supportMinimalUserInterface = true
The result of this is to expose a /uploadm path. The path depends on how this is deployed:
Via Docker: http://DOCKER_MACHINE:8080/json/order/uploadm
On the Test Bed: https://www.itb.ec.europa.eu/json/order/uploadm
The minimal interface offers largely the same functionality as the complete one but with a more condensed layout and minimal styling. The initial input page you see for the validator is as follows:

The most significant difference is the result page which provides initially only the overview and the relevant download controls:
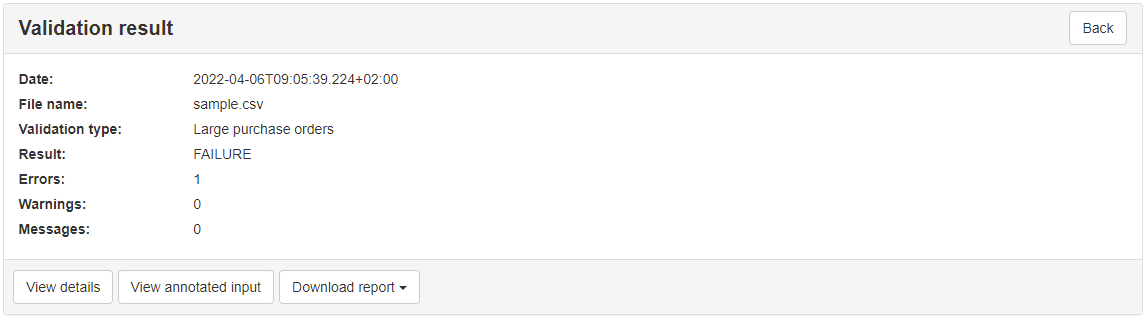
You can switch to display the detailed findings by clicking the View details button in which case you will also see the relevant findings’ filtering controls. All controls and displayed information for the input as well as the summary and detailed result pages are identical to the complete user interface (see Validation via user interface).
Validation via embedded interface
In case you want to use the validator through an existing web application the typical approach would be to use the validator’s machine-to-machine interface (via REST API or SOAP API). This allows you to present your own user interface to users while integrating with the validator in the background to validate provided data.
An alternative to this integration is to embed the validator’s user interface directly within your own user interface. This is possible for web applications but also for simple websites that would collect input data and provide it to the validator. When embedding the validator in this way you define an iframe in your interface’s HTML and set its source to point to the validator. Doing as such, results in the validator’s user interface displayed within your own, placed inside the defined iframe.
When embedding the validator in this way you have the following options available:
You may embed the validator’s complete user interface as-is. To do this set the source of the iframe to the validator’s interface (e.g.
https://www.itb.ec.europa.eu/csv/order/upload).Alternatively you may embed the validator’s minimal user interface (if enabled) for a more concise presentation. To do this set the source of the iframe to the validator’s minimal interface variant (
/uploadminstead of/upload).If you want to manage data input yourself you may skip the validator’s input form, using it only to display validation results. In this case you would typically use the validator’s minimal user interface as its result display does not include an input form.
If you are using the validator only to display results (i.e. the last option above), you will need to manage data input yourself and provide it to the validator
as it expects. To do this you include your inputs in a form that will need to be submitted to the validator via a HTTP POST request. The request
parameters you may provide are listed in the following table:
Input name |
Input type |
Description |
Required? |
|---|---|---|---|
|
file |
The file to validate. If provided the form must be a set as |
One of |
|
text |
The URI from which to load the content to validate. |
One of |
|
text |
The text to validate. |
One of |
|
text |
The type of input to consider (use |
Skip if only one of |
|
text |
The type of validation to perform (as defined in the validator’s configuration). |
Required unless the validator only defines a single validation type. |
The following HTML sample is a simple web page that provides a file input control for its users:
<html>
<head><title>Simple validator</title></head>
<body>
<h1>Validate your data</h1>
<form method="POST" enctype="multipart/form-data" action="https://www.itb.ec.europa.eu/csv/order/uploadm" target="output">
<input type="file" name="file">
<input type="hidden" name="validationType" value="large">
<button type="submit">Validate</button>
</form>
<iframe name="output" style="width:100%; height:50%;" src='about:blank'></iframe>
</body>
</html>
In the above sample take note of the following points:
Our input control is a file upload whereas the validation type is fixed and hidden. As we have a file upload, the enclosing form is set to make a multipart submission.
The validator interface to be used to display the results is the minimal interface (identified by the
/uploadmpath).The validation result is displayed in an iframe named output. This is set to be initially empty.
The validation submission, a HTTP
POST, is set to target the iframe. Once the validation is complete the iframe will display the output.
The following screenshot shows how the above configuration would appear once a validation has taken place.
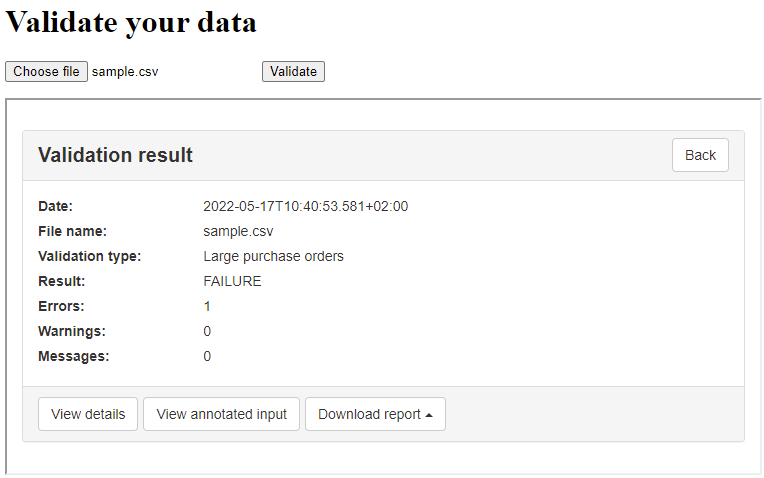
Note
Disable validator embedding: For the validator to be embedded it needs to allow itself to be presented in iframes. If you prefer to disable this feature
(see why here) you may set property validator.supportUserInterfaceEmbedding to false.
Validation via REST web service API
The validator’s REST API is available under the /csv/DOMAIN/api path. The exact path depends on how this is deployed:
Via Docker: http://DOCKER_MACHINE:8080/csv/order/api
On the Test Bed: https://www.itb.ec.europa.eu/csv/order/api
The operations that the REST API supports are the following:
Operation |
Description |
HTTP method |
Request payload type |
|---|---|---|---|
|
Retrieve the available validation types for a given domain (or for all domains). |
|
None |
|
Validate one CSV document. |
|
|
|
Validate multiple CSV documents. |
|
|
The supported operations as well their input and output are thoroughly documented using OpenAPI and Swagger. The documentation can be accessed online at the /csv/swagger-ui.html path.
The Swagger UI is notable as this provides rich, interactive documentation that can also be used to call the underlying operations. To access this navigate to:
If running via Docker: http://DOCKER_MACHINE:8080/csv/swagger-ui.html
If running on the Test Bed: https://www.itb.ec.europa.eu/csv/swagger-ui.html
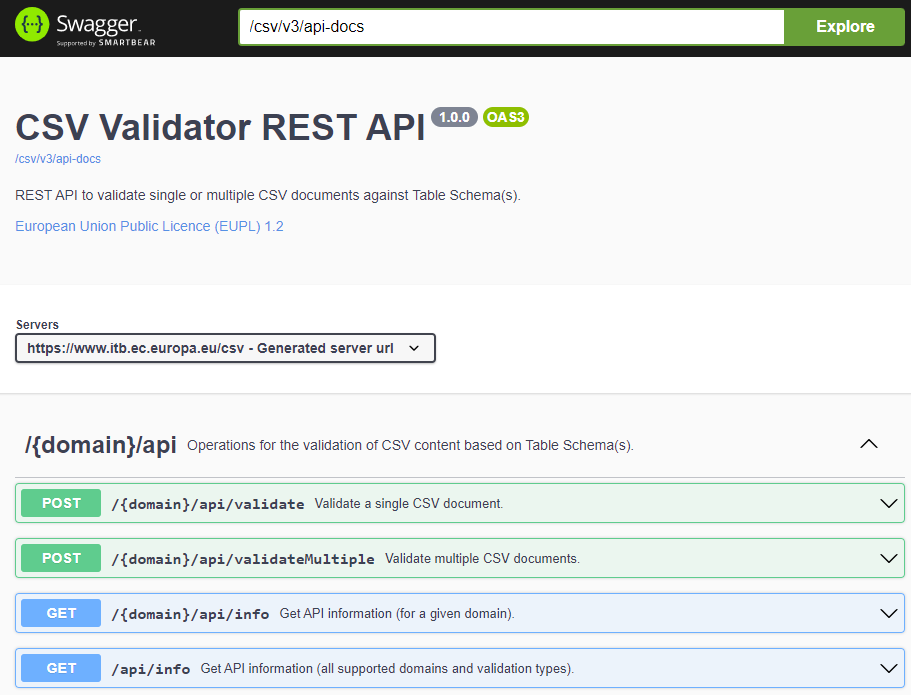
Note that before using the Swagger UI to execute any of the operations you will also need to specify the {domain} path parameter. In the
example we have been following this would be order.
Coming back to the specific operations supported, the first one to address is the info operation. This can be useful if the validator is configured
with multiple validation types in which case this service returns each type’s name and description.
Considering our order example making a GET request to http://DOCKER_MACHINE:8080/csv/order/api/info (or https://www.itb.ec.europa.eu/csv/order/api/info
on the Test Bed), you receive a JSON response as follows:
{
"domain": "order",
"validationTypes": [
{
"type": "basic",
"description": "Basic purchase order"
},
{
"type": "large",
"description": "Large purchase order"
}
]
}
To trigger validation of a CSV document you use the validate operation by making a POST request of type application/json to
http://DOCKER_MACHINE:8080/csv/order/api/validate (or https://www.itb.ec.europa.eu/csv/order/api/validate on the Test Bed). The payload
of the validate operation defines the following properties:
Property |
Description |
Required? |
Type |
Default value |
|---|---|---|---|---|
|
The content to validate. |
Yes |
A string that is interpreted based on the |
|
|
The way in which to interpret the |
No |
One of |
|
|
The type of validation to perform. |
Yes, unless a single validation type is defined. |
String |
The single configured validation type (if defined). |
|
An array of user-provided Table schemas to be considered with any predefined ones. These are accepted only if explicitly allowed in the configuration for the validation type in question. |
No |
An array of |
|
|
Whether the CSV content to validate includes a header row. |
No |
Boolean |
|
|
The field delimiter to consider. |
No |
String |
|
|
The field quote character to consider. |
No |
String |
|
|
The violation level in case the input field count doesn’t match the schema field count ( |
No |
String |
|
|
The violation level in case the input fields’ sequence doesn’t match the schema fields’ sequence ( |
No |
String |
|
|
The violation level in case the input field count doesn’t match the schema field count ( |
No |
String |
|
|
The violation level in case input fields match schema fields but with different casing ( |
No |
String |
|
|
The violation level in case multiple input fields map to the same schema field ( |
No |
String |
|
|
The violation level in case of unknown input fields ( |
No |
String |
|
|
The violation level in case schema fields are not defined ( |
No |
String |
|
|
Locale (language code) to use for reporting of results. If the provided locale is not supported by the validator the default locale will be used instead (e.g. “fr”, “fr_FR”). See Supporting multiple languages for details. |
No |
String |
|
|
Whether to include the validated input in the resulting report’s context section. |
No |
Boolean |
|
|
Whether to wrap the input (see addInputToReport) in a CDATA block if producing an XML report. False results in adding the input via XML escaping. |
No |
Boolean |
|
In case user-provided Table schemas are supported, these are provided as SchemaInfo entries as elements of the externalSchemas array. The content
of each SchemaInfo is as follows:
Property |
Description |
Required? |
Type |
Default value |
|---|---|---|---|---|
|
The schema’s content. |
Yes |
A string that is interpreted based on the |
|
|
The way in which to interpret the value for |
No |
One of |
Note
URI inputs: URI inputs ar disabled by default to prevent Server-Side Request Forgery (SSRF) attacks. You may
enable these at application-level (via property validator.allowUriInputs), and specifying a whitelist of
trusted base URIs (via property validator.allowedUriInputs).
To illustrate how this operation can be used we will consider a purchase order that will fail validation when checked to be of large type due to it lacking the required quantities per item:
shippingAddressName,shippingAddressStreet,shippingAddressCity,shippingAddressZip,billingAddressName,billingAddressStreet,billingAddressCity,billingAddressZip,orderDate,comment,totalItemQuantity,totalItemCostEUR
John Doe,Europa Avenue 123,Brussels,1000,Jane Doe,Europa Avenue 210,Brussels,1000,2020-01-22,Send in one package please,35,40.99
John Doe,Europa Avenue 123,Brussels,1000,Jane Doe,Europa Avenue 210,Brussels,1000,2020-01-23,,12,120.50
John Doe,Europa Avenue 123,Brussels,1000,Jane Doe,Europa Avenue 210,Brussels,1000,2020-01-24,,5,10.30
As a first validation example we will provide the content to validate as a URI to be looked up:
{
"contentToValidate": "https://www.itb.ec.europa.eu/files/samples/csv/sample-invalid.csv",
"validationType": "large"
}
In the contentToValidate parameter we include the URI to the file whereas in the validationType parameter we select the desired
validation type. Note that we need to define the validation type as we have more than one configured for purchase orders. If there was only
one this parameter would be optional.
The response returned for this call will be the validation report in the XML GITB TRL syntax:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<TestStepReport xmlns="http://www.gitb.com/tr/v1/" xmlns:ns2="http://www.gitb.com/core/v1/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="TAR">
<date>2022-11-14T16:41:38.465Z</date>
<result>FAILURE</result>
<counters>
<nrOfAssertions>0</nrOfAssertions>
<nrOfErrors>1</nrOfErrors>
<nrOfWarnings>0</nrOfWarnings>
</counters>
<context/>
<reports>
<error xsi:type="BAR">
<description>[Row: 4][Field: totalItemQuantity]: Value '5' for field 'totalItemQuantity' is less than the minimum of 10.</description>
<location>contentToValidate:4:0</location>
<value>5</value>
</error>
</reports>
</TestStepReport>
In this report we can see the overall validation result (FAILURE), its timestamp, as well as the individual report items (one in this case). Each
such item includes:
The item’s description.
The item’s location (expressed as the row and column location in the provided input).
In addition to the validation’s result you may also include as context information in the produced report the input data that was considered.
To do this specify in the call addInputToReport setting it to true:
{
"contentToValidate": "https://www.itb.ec.europa.eu/files/samples/csv/sample-invalid.csv",
"validationType": "large",
"addInputToReport": true
}
Doing so will include a context section in the report with the validated data:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<TestStepReport xmlns="http://www.gitb.com/tr/v1/" xmlns:ns2="http://www.gitb.com/core/v1/" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="TAR">
...
<context>
<ns2:item embeddingMethod="STRING" mimeType="text/csv" name="contentToValidate" type="string">
<ns2:value>shippingAddressName,shippingAddressStreet,...</ns2:value>
</ns2:item>
</context>
<reports>
...
</reports>
</TestStepReport>
Note
CDATA vs XML-escaping: By default context data is added to the report using XML escaping. If you would prefer that
CDATA blocks are used instead you may specify wrapReportDataInCDATA as true.
In case you would want to display the report’s XML in a user-friendly manner, the Test Bed makes available XSL stylesheets
to transform it to HTML. This provides an alternative to using the validator’s user interface,
when you need to work with a REST API but still want to present the resulting report as-is. Stylesheets for all official
EU languages are available in a ZIP bundle, whereas
individual stylesheets per language can also be accessed directly using the following URL (replace LANGUAGE with your desired language’s
two-letter ISO code):
https://www.itb.ec.europa.eu/files/stylesheets/gitb_trl/gitb_trl_stylesheet_v1.0.LANGUAGE.xsl.
The validation report may also be obtained in JSON format by specifying the HTTP Accept header and setting it to application/json. The JSON report
corresponding to the previous validation would be as follows:
{
"date": "2022-11-14T16:41:21.092+0000",
"result": "FAILURE",
"counters": {
"nrOfAssertions": 0,
"nrOfErrors": 1,
"nrOfWarnings": 0
},
"context": {},
"reports": {
"error": [
{
"description": "[Row: 4][Field: totalItemQuantity]: Value '5' for field 'totalItemQuantity' is less than the minimum of 10.",
"location": "contentToValidate:4:0",
"value": "5"
}
]
}
}
When calling the validator we used the contentToValidate property to provide the input via remote URL. You may also choose to embed the content to
be validated within the request itself either as a string (with appropriate JSON escaping) or as a BASE64 encoded string. When passing a
string, the request would resemble the following:
{
"contentToValidate": "shippingAddressName,shippingAddressStreet,shippingAddressCity,shippingAddressZip,billingAddressName,billingAddressStreet,billingAddressCity,billingAddressZip,orderDate,comment,totalItemQuantity,totalItemCostEUR\r\nJohn Doe,Europa Avenue 123,Brussels,1000,Jane Doe,Europa Avenue 210,Brussels,1000,2020-01-22,Send in one package please,35,40.99\r\nJohn Doe,Europa Avenue 123,Brussels,1000,Jane Doe,Europa Avenue 210,Brussels,1000,2020-01-23,,12,120.50\r\nJohn Doe,Europa Avenue 123,Brussels,1000,Jane Doe,Europa Avenue 210,Brussels,1000,2020-01-24,,5,10.30",
"validationType": "large"
}
In case of a BASE64 encoded string, the request would be as follows:
{
"contentToValidate": "c2hpcHBpbmdBZGRyZXNzTmFtZSxzaGlwcGluZ0FkZHJlc3NTdHJlZXQsc2hpcHBpbmdBZGRyZXNzQ2l0eSxzaGlwcGluZ0FkZHJlc3NaaXAsYmlsbGluZ0FkZHJlc3NOYW1lLGJpbGxpbmdBZGRyZXNzU3RyZWV0LGJpbGxpbmdBZGRyZXNzQ2l0eSxiaWxsaW5nQWRkcmVzc1ppcCxvcmRlckRhdGUsY29tbWVudCx0b3RhbEl0ZW1RdWFudGl0eSx0b3RhbEl0ZW1Db3N0RVVSCkpvaG4gRG9lLEV1cm9wYSBBdmVudWUgMTIzLEJydXNzZWxzLDEwMDAsSmFuZSBEb2UsRXVyb3BhIEF2ZW51ZSAyMTAsQnJ1c3NlbHMsMTAwMCwyMDIwLTAxLTIyLFNlbmQgaW4gb25lIHBhY2thZ2UgcGxlYXNlLDM1LDQwLjk5CkpvaG4gRG9lLEV1cm9wYSBBdmVudWUgMTIzLEJydXNzZWxzLDEwMDAsSmFuZSBEb2UsRXVyb3BhIEF2ZW51ZSAyMTAsQnJ1c3NlbHMsMTAwMCwyMDIwLTAxLTIzLCwxMiwxMjAuNTAKSm9obiBEb2UsRXVyb3BhIEF2ZW51ZSAxMjMsQnJ1c3NlbHMsMTAwMCxKYW5lIERvZSxFdXJvcGEgQXZlbnVlIDIxMCxCcnVzc2VscywxMDAwLDIwMjAtMDEtMjQsLDUsMTAuMzA=",
"validationType": "large"
}
In each of these cases, the validator will attempt to determine how the provided contentToValidate should be treated based on its format. To
speed up this process it is advised to specify the embeddingMethod input that makes the input processing approach explicit.
{
"contentToValidate": "QHBy...CAu",
"embeddingMethod": "BASE64",
"validationType": "large"
}
Finally, recall that in Step 3: Prepare validator configuration the possibility was mentioned to allow for a given validation type, user-provided schemas as
part of the validator’s input. To do this through the REST API you provide the externalSchemas array containing objects with two properties:
schemafor the content of the Table schema to consider.
embeddingMethod(STRING,URLorBASE64) to determine how theschemavalue is to be considered. As in the case of the input, this can be omitted but making it explicit is advised to speed up validation.
The following example illustrates how a user could provide two schemas to consider for the validation:
{
"contentToValidate": "ewo...Qp9",
"embeddingMethod": "BASE64",
"externalSchemas": [
{
"schema": "ewo...gfQ==",
"embeddingMethod": "BASE64"
},
{
"schema": "ewo...CB9",
"embeddingMethod": "BASE64"
}
]
}
Note
Blocking user-provided schemas: If you provide schemas where this has not been explicitly allowed the call will fail.
The remaining operation that is available is validateMultiple that can be used for batch validation. In this case the input to the service uses the same
JSON structure but this time as an array. To use the operation submit a POST request of type application/json to http://DOCKER_MACHINE:8080/csv/order/api/validateMultiple
(or https://www.itb.ec.europa.eu/csv/order/api/validateMultiple on the Test Bed).
In the following example two distinct validations are requested:
[
{
"contentToValidate": "https://www.itb.ec.europa.eu/files/samples/csv/sample.csv",
"validationType": "basic"
},
{
"contentToValidate": "https://www.itb.ec.europa.eu/files/samples/csv/sample-invalid.csv",
"validationType": "large"
}
]
The resulting response in this case always includes the reports as BASE64 encoded strings:
[
{
"report": "PD9...DQo="
},
{
"report": "PD9...DQo="
}
]
Validation via SOAP web service API
The validator’s SOAP API is available under the /csv/soap path. The exact path depends on how this is deployed (path to WSDL provided):
Via Docker: http://DOCKER_MACHINE:8080/csv/soap/order/validation?wsdl
On the Test Bed: https://www.itb.ec.europa.eu/csv/soap/order/validation?wsdl
The SOAP API used is the GITB validation service API, meaning that the validator is a GITB-compliant validation service. The importance of this is that apart from using it directly, this SOAP API allows integration of the validator in more complex conformance testing scenarios as a validation step in GITB TDL test cases. This potential is covered further in Step 7: Use the validator in GITB TDL test cases.
The operations supported are as follows:
getModuleDefinition: Called to return information on how to call the service (i.e. what inputs are expected).
validate: Called to trigger validation for provided content.
You can download this SOAP UI project that includes sample calls of these
operations (make sure to change the service URL to match your setup).
Regarding the getModuleDefinition operation, a request of:
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:v1="http://www.gitb.com/vs/v1/">
<soapenv:Header/>
<soapenv:Body>
<v1:GetModuleDefinitionRequest/>
</soapenv:Body>
</soapenv:Envelope>
Will produce a response as follows:
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<soap:Body>
<ns4:GetModuleDefinitionResponse xmlns:ns2="http://www.gitb.com/core/v1/" xmlns:ns3="http://www.gitb.com/tr/v1/" xmlns:ns4="http://www.gitb.com/vs/v1/">
<module operation="V" id="ValidatorService">
<ns2:metadata>
<ns2:name>ValidatorService</ns2:name>
<ns2:version>1.0.0</ns2:version>
</ns2:metadata>
<ns2:inputs>
<ns2:param type="binary" name="contentToValidate" use="R" kind="SIMPLE" desc="The content to validate, provided as a string, BASE64 or a URI."/>
<ns2:param type="string" name="embeddingMethod" use="O" kind="SIMPLE" desc="The embedding method to consider for the 'contentToValidate' input ('BASE64', 'URL' or 'STRING')."/>
<ns2:param type="string" name="validationType" use="O" kind="SIMPLE" desc="The type of validation to perform (if multiple types are supported)."/>
<ns2:param type="boolean" name="hasHeaders" use="O" kind="SIMPLE" desc="A boolean flag specifying whether the provided input contains as its first line the header definitions."/>
<ns2:param type="string" name="delimiter" use="O" kind="SIMPLE" desc="The character to be used as the field delimiter."/>
<ns2:param type="string" name="quote" use="O" kind="SIMPLE" desc="The character to be used as the quote character."/>
<ns2:param type="map" name="schema" use="O" kind="SIMPLE" desc="A map that defines the external Table Schema to consider. The map's items define the following keys: 'content' (the schema content to consider, see 'contentToValidate' for its semantics), 'embeddingMethod' (the way to consider the 'content' value)."/>
</ns2:inputs>
</module>
</ns4:GetModuleDefinitionResponse>
</soap:Body>
</soap:Envelope>
This response can be customised through configuration properties in config.properties to provide descriptions specific to your
setup. For example, extending config.properties with the following:
...
validator.webServiceId = PurchaseOrderValidator
validator.webServiceDescription.contentToValidate = The purchase order content to validate.
validator.webServiceDescription.validationType = The type of validation to perform ('basic' or 'large').
Will produce a response as follows:
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<soap:Body>
<ns4:GetModuleDefinitionResponse xmlns:ns2="http://www.gitb.com/core/v1/" xmlns:ns3="http://www.gitb.com/tr/v1/" xmlns:ns4="http://www.gitb.com/vs/v1/">
<module operation="V" id="ValidatorService">
<ns2:metadata>
<ns2:name>PurchaseOrderValidator</ns2:name>
<ns2:version>1.0.0</ns2:version>
</ns2:metadata>
<ns2:inputs>
<ns2:param type="binary" name="contentToValidate" use="R" kind="SIMPLE" desc="The purchase order content to validate."/>
<ns2:param type="string" name="embeddingMethod" use="O" kind="SIMPLE" desc="The embedding method to consider for the 'contentToValidate' input ('BASE64', 'URL' or 'STRING')."/>
<ns2:param type="string" name="validationType" use="O" kind="SIMPLE" desc="The type of validation to perform ('basic' or 'large')."/>
<ns2:param type="boolean" name="hasHeaders" use="O" kind="SIMPLE" desc="A boolean flag specifying whether the provided input contains as its first line the header definitions."/>
<ns2:param type="string" name="delimiter" use="O" kind="SIMPLE" desc="The character to be used as the field delimiter."/>
<ns2:param type="string" name="quote" use="O" kind="SIMPLE" desc="The character to be used as the quote character."/>
<ns2:param type="map" name="schema" use="O" kind="SIMPLE" desc="A map that defines the external Table Schema to consider. The map's items define the following keys: 'content' (the schema content to consider, see 'contentToValidate' for its semantics), 'embeddingMethod' (the way to consider the 'content' value)."/>
</ns2:inputs>
</module>
</ns4:GetModuleDefinitionResponse>
</soap:Body>
</soap:Envelope>
Running the validation itself is done through the validate operation. This expects the following inputs:
Input |
Description |
Required? |
Type |
Default value |
|---|---|---|---|---|
|
The CSV content to validate. |
Yes |
A string that is interpreted based on the |
|
|
The way in which to interpret the |
Yes, but should be skipped in favour of the |
One of |
|
|
The type of validation to perform. |
Yes, unless a single validation type is defined. |
String |
The single configured validation type (if defined). |
|
A user-provided Table Schema to be considered with any predefined one(s). This is accepted only if explicitly allowed in the configuration for the validation type in question. |
No |
A map (see below for content). |
|
|
Whether the content to validate contains a header row. This is taken into account only if configured for the validation type in question. |
No |
Boolean |
|
|
The delimiter character used to separate fields in the provided content. This is taken into account only if configured for the validation type in question. |
No |
String |
|
|
The quote character used to optionally wrap field values. This is taken into account only if configured for the validation type in question. |
No |
String |
|
|
The violation level when the number of input fields doesn’t match the number of schema fields. This is taken into account only if configured for the validation type in question. |
No |
One of |
|
|
The violation level when the sequence of input fields doesn’t match the one defined in the schema. This is taken into account only if configured for the validation type in question. |
No |
One of |
|
|
The violation level when duplicate input fields are found. This is taken into account only if configured for the validation type in question. |
No |
One of |
|
|
The violation level when a field’s name doesn’t match the casing defined in the schema. This is taken into account only if configured for the validation type in question. |
No |
One of |
|
|
The violation level when multiple input fields map to the same schema field. This is taken into account only if configured for the validation type in question. |
No |
One of |
|
|
The violation level when an unknown input field is detected. This is taken into account only if configured for the validation type in question. |
No |
One of |
|
|
The violation level when a schema field does not have a corresponding value in the input. This is taken into account only if configured for the validation type in question. |
No |
One of |
|
|
Whether the validated input should be included in the produced response as the report’s context. |
No |
|
|
|
Locale (language code) to use for reporting of results. If the provided locale is not supported by the validator the default locale will be used instead (e.g. “fr”, “fr_FR”). See Supporting multiple languages for details. |
No |
String |
Note
Configuration for increased throughput: If you expect to be validating large CSV files and/or with high frequency it
would be advised to call the validator setting addInputToReport to false to avoid including the validated content
(which could be large) in the resulting report’s context. For huge CSV files that can potentially reach several gigabytes
in size it is of course advised that validation is not done via web application at all but rather using the
command line tool.
Regarding the schema input, this is treated as a map with two properties:
Input |
Description |
Required? |
Type |
|---|---|---|---|
|
The schema content to consider. |
Yes |
A string that is interpreted based on the |
|
The way in which to interpret the |
No |
One of |
As an alternative to the embeddingMethod inputs, the GITB SOAP API foresees also the embeddingMethod attribute that is defined on each input element. The values it supports are:
Value |
Description |
|---|---|
|
The value is interpreted as-is as an embedded text. |
|
The value is interpreted as an embedded BASE64 string that will need to be decoded before processing. |
|
The value is interpreted as a remote URI reference that will be looked up before processing. |
Note
embeddingMethod values: The two approaches to provide the embeddingMethod value (as an input or an attribute) is due to a known issue in the GITB software where not all embedding methods can be
leveraged in test cases (see Step 7: Use the validator in GITB TDL test cases).
Note that URI inputs ar disabled by default to prevent Server-Side Request Forgery (SSRF) attacks. You may
enable these at application-level (via property validator.allowUriInputs), and specifying a whitelist of
trusted base URIs (via property validator.allowedUriInputs).
The sample SOAP UI project includes sample requests per case. As an example,
validating via URI would be done using the following envelope:
<soapenv:Envelope xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns:v1="http://www.gitb.com/vs/v1/" xmlns:v11="http://www.gitb.com/core/v1/">
<soapenv:Header/>
<soapenv:Body>
<v1:ValidateRequest>
<sessionId>?</sessionId>
<input name="contentToValidate" embeddingMethod="URI">
<v11:value>https://www.itb.ec.europa.eu/files/csv/sample.csv</v11:value>
</input>
<input name="validationType" embeddingMethod="STRING">
<v11:value>large</v11:value>
</input>
</v1:ValidateRequest>
</soapenv:Body>
</soapenv:Envelope>
With the resulting report provided as follows:
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<soap:Body>
<ns4:ValidationResponse xmlns:ns2="http://www.gitb.com/core/v1/" xmlns:ns3="http://www.gitb.com/tr/v1/" xmlns:ns4="http://www.gitb.com/vs/v1/">
<report>
<ns3:date>2020-09-23T15:58:42.975+02:00</ns3:date>
<ns3:result>FAILURE</ns3:result>
<ns3:counters>
<ns3:nrOfAssertions>0</ns3:nrOfAssertions>
<ns3:nrOfErrors>1</ns3:nrOfErrors>
<ns3:nrOfWarnings>0</ns3:nrOfWarnings>
</ns3:counters>
<ns3:context>
<ns2:item name="contentToValidate" embeddingMethod="STRING" type="string">
<ns2:value>shippingAddressName,shippingAddressStreet,shippingAddressCity,shippingAddressZip,billingAddressName,billingAddressStreet,billingAddressCity,billingAddressZip,orderDate,comment,totalItemQuantity,totalItemCostEUR
John Doe,Europa Avenue 123,Brussels,1000,Jane Doe,Europa Avenue 210,Brussels,1000,2020-01-22,Send in one package please,35,40.99
John Doe,Europa Avenue 123,Brussels,1000,Jane Doe,Europa Avenue 210,Brussels,1000,2020-01-23,,12,120.50
John Doe,Europa Avenue 123,Brussels,1000,Jane Doe,Europa Avenue 210,Brussels,1000,2020-01-24,,5,10.30</ns2:value>
</ns2:item>
</ns3:context>
<ns3:reports>
<ns3:error xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="ns3:BAR">
<ns3:description>[4][totalItemQuantity]: Value '5' for field 'totalItemQuantity' is less than the minimum of 10.</ns3:description>
<ns3:location>contentToValidate:4:0</ns3:location>
<ns3:value>5</ns3:value>
</ns3:error>
</ns3:reports>
</report>
</ns4:ValidationResponse>
</soap:Body>
</soap:Envelope>
The returned report uses the GITB TRL syntax and is the same as the XML report you can download from the user interface (see Validation via user interface). It includes:
The validation timestamp (in UTC).
The overall result (
SUCCESSorFAILURE).The count of errors, warnings and information messages.
The context for the validation (i.e. the CSV content that was validated).
The list of report items displaying per item its description and location in the validated content.
Validation via command-line tool
Note
Command-line tool availability: Command-line tools are supported only for validators hosted on Test Bed resources and if generation of such a tool has been requested (see Step 5: Setup validator on Test Bed).
When a command line tool is set up for your validator it is available as an executable JAR file, packaged alongside a README file in a ZIP archive.
This ZIP archive is downloadable from a URL of the form https://www.itb.ec.europa.eu/csv-offline/DOMAIN/validator.zip, where DOMAIN is the
name of the validator’s domain. Considering our purchase order example, the command-line validator would be available at https://www.itb.ec.europa.eu/csv-offline/order/validator.zip.
To use it you need to:
Ensure you have Java running on your workstation (minimum version 17).
Download and extract the validator’s ZIP archive.
Open a command prompt and change to the directory in which you extracted the JAR file.
View the validator’s help message by issuing
java -jar validator.jar
> java -jar validator.jar
Expected usage: java -jar validator.jar -input FILE_OR_URI_1 ... [-input FILE_OR_URI_N] [-noreports] [-schema SCHEMA_FILE_OR_URI] [-locale LOCALE]
Where:
- FILE_OR_URI_X is the full file path or URI to the content to validate.
- SCHEMA_FILE_OR_URI is the full file path or URI to a schema for the validation.
- LOCALE is the language code to consider for reporting of results. If the provided locale is not supported by the validator the default locale will be used instead (e.g. 'fr', 'fr_FR').
The summary of each validation will be printed and the detailed reports produced in the current directory (as "report.X.xml", "report.X.pdf" and "report.X.csv").
Running the validator will produce a summary output on the command console as well as the detailed validation report(s) (unless flag -noreports has
been specified). To resolve potential problems during execution, an output log is also generated with a detailed log trace.
> java -jar validator.jar -input sample.csv
Validating 1 of 1 ... Done.
Validation report summary [sample.csv]:
- Date: 2020-12-07T17:53:03.396+01:00
- Result: FAILURE
- Errors: 1
- Warnings: 0
- Messages: 0
- Detailed reports in [D:\tmp\report.0.xml], [D:\tmp\report.0.pdf] and [D:\tmp\report.0.csv]
Note
Offline validator use and remote files: Depending on the validator’s configuration, one or more of its configured Table Schemas may be defined as URIs (see Step 3: Prepare validator configuration). In addition, you may also provide the content to validate as a reference to a remote file. In these cases the workstation running the validator would need access to the remote resources. Any proxy settings applicable for the workstation will automatically be used for the connections.
Step 7: Use the validator in GITB TDL test cases
As a next step over the standalone CSV validator you may consider using it from within GITB TDL test cases running in the Test Bed. You would typically do this for the following reasons:
You want to control access to the validation service based on user accounts.
You prefer to record all data linked to validations (for e.g. subsequent inspection).
You want to build complete conformance testing scenarios that are either focused on the validator or that use it as part of validation steps.
As described in Validation via SOAP web service API, the standalone CSV validator offers by default a SOAP API for machine-to-machine
integration that realises the GITB validation service specification. In short this means that the service can be easily included in any GITB TDL
test case as the handler of a verify step. This is done by supplying as the handler value the full URL to the service’s WSDL, as illustrated in the following example that
requests the user to upload the file to validate:
<?xml version="1.0" encoding="UTF-8"?>
<testcase id="testCase1_upload" xmlns="http://www.gitb.com/tdl/v1/" xmlns:gitb="http://www.gitb.com/core/v1/">
<metadata>
<gitb:name>[TC1] Validate user-provided data</gitb:name>
<gitb:version>1.0</gitb:version>
<gitb:description>Test case that allows the developer of an EU retailer system to upload a purchase order CSV file for validation.</gitb:description>
</metadata>
<actors>
<gitb:actor id="Retailer" name="Retailer" role="SUT"/>
</actors>
<steps>
<!--
Request from the user the content to validate.
-->
<interact id="userData" desc="Upload content">
<request name="content" desc="Purchase order to validate:" inputType="UPLOAD"/>
</interact>
<!--
Trigger the validation.
-->
<verify handler="https://www.itb.ec.europa.eu/csv/soap/order/validation?wsdl" desc="Validate purchase order">
<input name="contentToValidate">$purchaseOrderFileToValidate</input>
<input name="validationType">"basic"</input>
</verify>
</steps>
</testcase>
The supported inputs for the verify step match those expected by the validator’s SOAP API (see Validation via SOAP web service API).
We included the validationType input because we define two validation types (basic and large) but this could be omitted if only a single validation type is supported.
For string or binary content you typically don’t need to provide the embeddingMethod input as this is determined
automatically by the Test Bed. If however you are using string variables that contain BASE64 or URI references you would need to define this explicitly.
An example of this is a test case that requests the content from the user as a URI:
<testcase id="testCase1_upload" xmlns="http://www.gitb.com/tdl/v1/" xmlns:gitb="http://www.gitb.com/core/v1/">
...
<steps>
<!--
Request from the user the content to validate as a URI.
-->
<interact id="userData" desc="Provide input">
<request name="content" desc="URI of the purchase order to validate:"/>
</interact>
<!--
Trigger the validation.
-->
<verify handler="https://www.itb.ec.europa.eu/csv/soap/order/validation?wsdl" desc="Validate purchase order">
<input name="contentToValidate">$userData{content}</input>
<!--
Explicitly define the embeddingMethod to consider.
-->
<input name="embeddingMethod">"URL"</input>
<input name="validationType">"large"</input>
</verify>
</steps>
</testcase>
A more complicated example is when external schemas are to be provided to apply alongside the validator’s built-in configuration (if supported for the validation type in question). The following example shows two such schemas being provided, one as a URI and one from a file included in the test suite itself:
<testcase id="testCase1_upload" xmlns="http://www.gitb.com/tdl/v1/" xmlns:gitb="http://www.gitb.com/core/v1/">
...
<imports>
<!--
Import the additional shapes to consider from the test suite.
-->
<artifact type="binary" name="additionalSchema">resources/additionalSchema.json</artifact>
</imports>
...
<steps>
<!--
Request from the user the content to validate.
-->
<interact id="userData" desc="Upload content">
<request name="content" desc="Purchase order to validate:" inputType="UPLOAD"/>
</interact>
<!--
Configure the remotely loaded schema.
-->
<assign to="$schema1{content}">"https://path.to.rules/schema.json"</assign>
<assign to="$schema1{embeddingMethod}">"URL"</assign>
<!--
Configure the schema loaded from the imported file.
-->
<assign to="$schema2{content}">additionalSchema</assign>
<!--
Add both to the input list.
-->
<assign to="externalSchemas" append="true">$schema1</assign>
<assign to="externalSchemas" append="true">$schema2</assign>
<!--
Trigger the validation.
-->
<verify handler="https://www.itb.ec.europa.eu/csv/soap/order/validation?wsdl" desc="Validate purchase order">
<input name="contentToValidate">$userData{content}</input>
<input name="validationType">"large"</input>
<!--
Pass the list of additional schemas to consider.
-->
<input name="schema">$externalSchemas</input>
</verify>
</steps>
</testcase>
One additional point to make is on the definition of the service’s WSDL (i.e. the handler value). Although you can define this directly as in the previous examples,
a better approach to improve portability is to define this in the Test Bed’s domain configuration as a domain parameter. Defining a validationService parameter
in the domain you could thus redefine the verify step as:
...
<verify handler="$DOMAIN{validationService}" desc="Validate purchase order">
...
</verify>
...
Summary
Congratulations! You have just set up a validation service for your CSV data specification. In doing so you considered your needs and defined your service through configuration on the DIGIT Test Bed or as a Docker container. In addition, you used this service via its different APIs and considered how this could be used as part of complete conformance testing scenarios.
See also
The validator for the fictional specification considered in this guide is available as a demo that you can use. The validator is available here, whereas its domain configuration repository is published as a sample on GitHub.
In Step 7: Use the validator in GITB TDL test cases we briefly touched upon using the Test Bed for complete conformance testing scenarios. If this interests you, several additional guides are available that can provide you with further information:
Guide: Creating a test suite on how to create a simple GITB TDL test suite.
Guide: Defining your test configuration on how to configure a GITB TDL test suite in the Test Bed as part of your overall test setup.
Guide: Executing a test case on how to execute tests and monitor results.
Guide: Installing the Test Bed for development use on how to install your own Test Bed instance to test with.
For the full information on GITB TDL test cases check out the GITB TDL documentation, the reference for all test step constructs as well as a source of numerous complete examples.
In case you need to consider validation of further content types, be aware that the Test Bed provides similar support for:
XML validation using XML Schema and Schematron.
RDF validation using SHACL shapes.
JSON validation using JSON Schema.
YAML validation using JSON Schema.
If you are planning on operating a validator on your own-premises for production use check the validator production installation guide for the steps to follow and guidelines to consider.
Finally, for more information on Docker and the commands used in this guide, check out the Docker online documentation.
References
This section contains additional references linked to this guide.
Validator configuration properties
The following sections list the configuration properties you can use to customise the operation of your validation service.
Domain-level configuration
The properties in this section are to be provided in the configuration property file (one per configured validation domain) you define as part of your validator configuration. The properties marked as being translatable (in the listed property Type) can also be defined in translation property files if the validator is configured to support multiple languages (see Supporting multiple languages).
Note
Property placeholders: Numerous configuration properties listed below are presented with placeholders. These are marked in uppercase and have the following meaning:
TYPE: The validation type to perform.
OPTION: An option for a given validation type (e.g. a specific version).
FULL_TYPE: For a validation type with options this is equals toTYPE.OPTION, otherwise it is theTYPEvalue itself.
N: A zero-based integer (used as a counter).
Property |
Description |
Type |
Default value |
|---|---|---|---|
|
Whether or not a UTF-8 BOM (Byte Order Mark) should be added when generating validation reports in CSV format. |
Boolean |
true |
|
Configurable HTML banner replacing the text title. |
String (translatable) |
|
|
Comma-separated list of validation channels to have enabled. Possible values are ( |
Comma-separated Strings |
form, rest_api, soap_api |
|
Label to display for the full validation type and option combination (visible in the validator’s result screen). |
String (translatable) |
|
|
A rich text message to display in PDF reports before the errors section. The base property can be extended with |
String (translatable) |
|
|
A rich text message to display in PDF reports before the messages section. The base property can be extended with |
String (translatable) |
|
|
A rich text message to display in PDF reports before the overview section. The base property can be extended with |
String (translatable) |
|
|
A rich text message to display in PDF reports before the warnings section. The base property can be extended with |
String (translatable) |
|
|
Paired with the its corresponding jar property (see above), this defines the fully qualified names of the classes to be loaded as plugin implementations. |
Comma-separated Strings |
|
|
Configuration for custom plugins that can be used to extend the validation. This is a default plugin definition that applies to all validation types. This property is the relative path pointing to the all-in-one JAR file that contains the plugin implementation(s). |
String |
|
|
The default validation type, considered if no type is indicated. |
String |
|
|
The delimiter character to use. |
Character |
, |
|
The violation level when the number of input fields doesn’t match the number of schema fields. Possible values are |
error |
|
|
The violation level when the sequence of input fields doesn’t match the defined sequence in the schema. Possible values are |
error |
|
|
In case the current domain is to be considered an alias, this is the target domain to delegate processing to. |
String |
|
|
Mapping for the given validation type (set as a postfix) in the current domain, to a validation type or alias in the target domain. |
String |
|
|
The violation level when duplicate input fields are found. Possible values are |
error |
|
|
Whether or not a user-provided schema is allowed for the given validation type (added as a postfix). Possible values are ( |
String |
none |
|
The authentication approach to use for requests ( |
String |
|
|
The name of the HTTP header to set when |
String |
|
|
The value of the HTTP header to set when |
String |
|
|
The password to use when |
String |
|
|
The reference to a configured OAuth service (see |
String |
|
|
The username to use when |
String |
|
|
Configurable HTML banner for the footer. |
String (translatable) |
|
|
Whether the input is expected to have a header row. |
Boolean |
true |
|
Comma separated list of validator types to hide in the web UI. Validator types listed here, will not be displayed in the web UI and will only be accessible through the CLI and the API. |
String |
none |
|
The HTTP protocol version to use when loading remote resources. Possible values are |
String |
2 |
|
The path of a file declaring additional domain properties. If the application property |
String |
|
|
Whether users may/must specify the delimiter character for the provided input. Possible values are ( |
String |
none |
|
Whether users may/must specify the violation level for a field count mismatch. Possible values are ( |
String |
none |
|
Whether users may/must specify the violation level for a field sequence mismatch. Possible values are ( |
String |
none |
|
Whether users may/must specify the violation level for duplicate input fields. Possible values are ( |
String |
none |
|
Whether users may/must specify if their provided input has headers. Possible values are ( |
String |
none |
|
Whether users may/must specify the violation level for a case difference in field names. Possible values are ( |
String |
none |
|
Whether users may/must specify the violation level when multiple input fields map to the same schema field. Possible values are ( |
String |
none |
|
Whether users may/must specify the quote character for the provided input. Possible values are ( |
String |
none |
|
Whether users may/must specify the violation level for unknown fields. Possible values are ( |
String |
none |
|
Whether users may/must specify the violation level for schema fields not covered in the input. Possible values are ( |
String |
none |
|
The violation level when the name of an input field does not match the casing defined in the schema. Possible values are |
error |
|
|
Configurable JavaScript content to support HTML banners and footers. |
String (translatable) |
|
|
The list of locales (language codes) that will be available for the user to select. This is provided as a comma-separated set of String values, the order of which determines the order that they will be listed in the UI’s language selection control. |
Comma-separated Strings |
|
|
The default locale (language code) to consider for the validator. This can be provided alone or with a country variant (e.g. “en”, “en_US”, “en_GB”). |
String |
en |
|
The path to a folder (absolute or relative to the domain configuration file) that contains the translation property files for the validator’s supported languages. |
String |
|
|
The maximum number of report items for which a PDF validation report will be generated (no report will be preoduced if exceeded). |
Integer |
5000 |
|
The maximum number of report items to include in the XML validation report. |
Integer |
|
|
The violation level when multiple input fields map to the same schema field. Possible values are |
error |
|
|
The client ID to use for OAuth 2.0 authentication when looking up remote resources. The |
String |
|
|
The client secret to use for OAuth 2.0 authentication when looking up remote resources. The |
String |
|
|
The URL from which to obtain tokens when using OAuth 2.0 authentication. The |
String |
|
|
Label to display in the web form for an option across all validation types (added as a postfix of |
String (translatable) |
|
|
Paired with the its corresponding jar property (see above), this defines the fully qualified names of the classes to be loaded as plugin implementations. |
Comma-separated Strings |
|
|
Configuration for custom plugins that can be used to extend the validation specific to a given type (FULL_TYPE) and extending any default plugins (see above). This property is the relative path pointing to the all-in-one JAR file that contains the plugin implementation(s). |
String |
|
|
The quote character to use. |
Character |
|
|
The default handling approach for errors raised when downloading pre-configured remote artefacts. Possible values are |
String |
log |
|
The handling approach for a given validation type for errors raised when downloading pre-configured remote artefacts. Possible values are |
String |
log |
|
A report identifier to include as metadata in produced GITB TRL reports (in XML or JSON format). |
String |
|
|
A report name to include as metadata in produced GITB TRL reports (in XML or JSON format). |
String |
|
|
The default value for a profile customisation ID to include as metadata in produced GITB TRL reports (in XML or JSON format). |
String |
|
|
The profile customisation ID for a given (full) validation type to include as metadata in produced GITB TRL reports (in XML or JSON format). |
String |
|
|
The default value for a profile ID to include as metadata in produced GITB TRL reports (in XML or JSON format). |
String |
The applied (full) validation type. |
|
The profile ID for a given (full) validation type to include as metadata in produced GITB TRL reports (in XML or JSON format). |
String |
|
|
A name for the validator to include as metadata in produced GITB TRL reports (in XML or JSON format). |
String |
|
|
A version for the validator to include as metadata in produced GITB TRL reports (in XML or JSON format). |
String |
|
|
Whether the report items are expected to contain rich text and will be rendered as such (currently links). |
Boolean |
false |
|
Comma-separated list of schema files loaded for a given validation type (added as a postfix). These can be a files or folders. |
Comma-separated Strings |
|
|
The authentication approach to use for requests ( |
String |
|
|
The name of the HTTP header to set when |
String |
|
|
The value of the HTTP header to set when |
String |
|
|
The password to use when |
String |
|
|
The reference to a configured OAuth service (see |
String |
|
|
Reference for a remotely loaded schema file for a given validation type (added as the |
String |
|
|
The username to use when |
String |
|
|
Whether or not to show the about panel on the web UI. |
Boolean |
true |
|
Whether or not to show the validation software version information on the web UI. |
Boolean |
true |
|
Enable a minimal user interface useful for embedding in other UIs or portals (applies only if the |
Boolean |
false |
|
Allow the validator to be embedded within other user interfaces by displaying it in iframes. |
Boolean |
true |
|
Comma-separated list of supported validation types. Values need to be reflected in the other properties’ |
Comma-separated Strings |
|
|
Comma-separated list of the validation types included in the group (see |
Comma-separated Strings |
|
|
Label to display in the web form for a given validation type group (added as a postfix of |
String (translatable) |
|
|
The presentation approach for validation type groups (if defined). Accepted values are |
String |
inline |
|
Label to display in the web form for a given validation type (added as a postfix of |
String (translatable) |
|
|
Comma-separated list of options defined for a given validation type (added as a postfix). Values need to be reflects in the other properties’ |
Comma-separated Strings |
|
|
An alias that points to a full validation type and will resolve to it when used. |
String |
|
|
Label to display for an option for a specific validation type. |
String (translatable) |
|
|
The violation level when an input field is not found in the schema fields. Possible values are |
error |
|
|
The violation level when a schema field is not provided for in the input. Possible values are |
error |
|
|
The description of the SOAP web service for element “addInputToReport”. |
String |
Whether the returned XML validation report should also include the validated input as context information. |
|
The description of the SOAP web service for element “contentToValidate”. |
String |
The content to validate, provided as a string, BASE64 or a URI. |
|
The description of the SOAP web service for element “delimiter”. |
String |
The character to be used as the field delimiter. |
|
The description of the SOAP web service for element “differentInputFieldCountViolationLevel”. |
String |
The violation level in case the input field count doesn’t match the schema field count (‘none’, ‘info’, ‘optional’, ‘required’). |
|
The description of the SOAP web service for element “differentInputFieldSequenceViolationLevel”. |
String |
The violation level in case the input fields’ sequence doesn’t match the schema fields’ sequence (‘none’, ‘info’, ‘optional’, ‘required’). |
|
The description of the SOAP web service for element “duplicateInputFieldsViolationLevel”. |
String |
The violation level in case the duplicate input fields are found (‘none’, ‘info’, ‘optional’, ‘required’). |
|
The description of the SOAP web service for element “embeddingMethod”. |
String |
The embedding method to consider for the ‘contentToValidate’ input (‘BASE64’, ‘URL’ or ‘STRING’). |
|
The description of the SOAP web service for element “fieldCaseMismatchViolationLevel”. |
String |
The violation level in case input fields match schema fields but with different casing (‘none’, ‘info’, ‘optional’, ‘required’). |
|
The description of the SOAP web service for element “hasHeaders”. |
String |
A boolean flag specifying whether the provided input contains as its first line the header definitions. |
|
The description of the SOAP web service for element “locale”. |
String |
Locale (language code) to use for reporting of results. If the provided locale is not supported by the validator the default locale will be used instead (e.g. “fr”, “fr_FR”). |
|
The description of the SOAP web service for element “multipleInputFieldsForSchemaFieldViolationLevel”. |
String |
The violation level in case multiple input fields map to the same schema field (‘none’, ‘info’, ‘optional’, ‘required’). |
|
The description of the SOAP web service for element “quote”. |
String |
The character to be used as the quote character. |
|
The description of the SOAP web service for element “schema”. |
String |
A map that defines the external Table Schema to consider. The map’s items define the following keys: ‘content’ (the schema content to consider, see ‘contentToValidate’ for its semantics), ‘embeddingMethod’ (the way to consider the ‘content’ value). |
|
The description of the SOAP web service for element “unknownInputFieldViolationLevel”. |
String |
The violation level in case of unknown input fields (‘none’, ‘info’, ‘optional’, ‘required’). |
|
The description of the SOAP web service for element “unspecifiedSchemaField”. |
String |
The violation level in case schema fields are not defined (‘none’, ‘info’, ‘optional’, ‘required’). |
|
The description of the SOAP web service for element “validationType”. Only displayed if there are multiple types. |
String |
The type of validation to perform (if multiple types are supported). |
|
The ID of the web service. |
String |
ValidatorService |
Application-level configuration
These properties govern the validator’s application instance itself. They apply only when you are defining your own validator
as a Docker image in which case they are supplied as environment variables (ENV directives in a Dockerfile). Note that
apart from these properties any Spring Boot configuration property can also be supplied.
Note
The only property that is mandatory for a custom validator setup is validator.resourceRoot. If you don’t provide this, a generic validator will be configured
for validation against user-provided validation artefacts.
Property |
Description |
Type |
Default value |
|---|---|---|---|
|
Path to a folder that will hold the validator’s log output. |
String |
/validator/logs |
|
The accepted mime types for user-provided content through the user interface. |
Comma-separated Strings |
text/csv, text/plain |
|
Accepted local schema file extensions. All other files found in |
Comma-separated Strings |
json |
|
Allow URIs to be provided as inputs for the content to validate and other artefacts. |
Boolean |
false |
|
The base URIs (provided as absolute URIs) for internal HTTP-based URIs that are allowed to be loaded as included or imported resources in schemas. |
Comma-separated Strings |
|
|
The base URIs (provided as absolute URIs) for URIs provided as inputs that will be considered as trusted and allowed to be loaded. |
Comma-separated Strings |
|
|
The full public base URL at which SOAP endpoints will be published (up to but without including the domain name). |
String |
|
|
The rate at which the external file cache is refreshed (in milliseconds). |
Long |
3600000 |
|
The rate at which temporary files linked to the web form are cleaned (in milliseconds). |
Long |
600000 |
|
The host to display as the root for the REST API Swagger documentation. |
String |
localhost:8080 |
|
Description of the licence in the Swagger UI. |
String, |
European Union Public Licence (EUPL) 1.2 |
|
URL to the licence for the Swagger UI. |
String, |
|
|
Comma-separated scheme values for the Swagger documentation |
Comma-separated Strings |
http |
|
Comma-separated server URL values for the Swagger documentation |
Comma-separated Strings |
|
|
Title to display in the Swagger UI. |
String, |
CSV Validator REST API |
|
Version number to display in the Swagger UI. |
String, |
1.0.0 |
|
The names of the domain subfolders to consider. By default all folders under |
Comma-separated Strings |
|
|
The name to display for a given domain folder (the folder name replacing the |
String |
The folder name is used. |
|
The validator’s identifier to be sent for usage statistics reporting. |
String |
csv |
|
The minimum time for which input provided through the web interface is cached (in milliseconds). |
Long |
600000 |
|
The minimum time for which reports generated through use of the web interface are cached (in milliseconds). |
Long |
600000 |
|
The maximum validations per minute through the web user interface. |
Integer |
60 |
|
The maximum validations per minute through the REST API (operation |
Integer |
60 |
|
The maximum validations per minute through the REST API (operation |
Integer |
30 |
|
The maximum validations per minute through the SOAP API. |
Integer |
60 |
|
Whether validation rate limiting is enabled. |
Boolean |
false |
|
The name of a HTTP header from which to read the client’s IP address. |
String |
|
|
Whether exceeding the rate limit will result in a logged warning as opposed to a blocked request. |
Boolean |
false |
|
The root folder under which domain subfolders will be loaded from. |
String |
|
|
Whether local validation artefacts can be loaded from outside the domain root folder. If |
Boolean |
true |
|
Path to a folder that contains temporary data and reports. |
String |
/validator/tmp |
|
The HTTP header to use to retrieve the user’s IP address for usage statistics if the validator is behind a proxy. This property is only used to detect the user’s country, when such feature is enabled (see |
String |
X-Real-IP |
|
The URL of the backend service that will collect usage statistics. This property is optional and, if (and only if) present, the validator will report usage statistics. |
String |
|
|
The path to the .mmdb file with the geolocation database that is used to resolve the user’s country from an IP address. This database will only be used when the property |
String |
|
|
Whether the usage statistics reporting service can detect users’ countries from their IP addresses. If |
Boolean |
false |
|
The validator client secret to be passed to the backend service for usage statistics reporting. |
String |