Export and import your data
A key part of your administration tasks is the configuration of your domain and user community to define your conformance testing setup and customise the experience of your users. This configuration involves significant data entry and upload of files (most importantly test suites) that can be time-consuming if needed to be replicated. Replicating this setup is nonetheless something that often needs to be done, typically as part of the following scenarios:
Development workflow: You are implementing your test cases in a local Test Bed instance that you use for development. Once ready you will want to replicate your configuration to the Test Bed instance your users will actually be using.
Setup of new Test Bed instance: You may need at some point to set up a new Test Bed instance that matches your community’s configuration. This could be the case when defining a separate environment (e.g. “TEST” and “ACCEPTANCE” environments) or when a new test developer joins the team and needs her own development instance.
Troubleshooting: If a specific organisation is facing issues with a test suite you may want to replicate its specific configuration in a separate Test Bed instance for further investigation.
Experimentation: When rolling out a new setup for a community you may want to initially set this up separately as a dry run of the configuration update.
Configuration of user-hosted Test Bed: As part of your conformance testing strategy you may want to allow users to set up an on-premise Test Bed instance as a tool to facilitate their implementation of the target specifications. Such Test Bed instances would need to be populated to offer a ready-to-use environment for your users. This case constitutes the set up of sandbox instances that is specifically addressed here.
One approach to carry out the above scenarios would be to manually create all data in the target Test Bed instance and upload the relevant test suites. Needless to say, for a non-trivial setup, this would be a very time-consuming and error-prone task. To address this, the Test Bed allows you to process data in bulk by means of:
Exporting data from the source Test Bed, selecting the information you want to export and generating an all-in-one data archive.
Importing data to the target Test Bed, providing a data archive and choosing how to apply its contents on the existing data.
Note
Using imports for minor modifications: The simplicity offered by generating and then importing data archives may appear as a valid replacement for manual data modifications even when these are very limited. You need to keep in mind that data export/import is suited for bulk operations and can have unwanted side-effects when applied to existing setups without being carefully reviewed.
In other words, don’t use such bulk operations as a replacement for uploading a new test suite or creating a new organisation.
Management of exports and imports take place in the data management screen, accessible by clicking the relevant link from the menu.
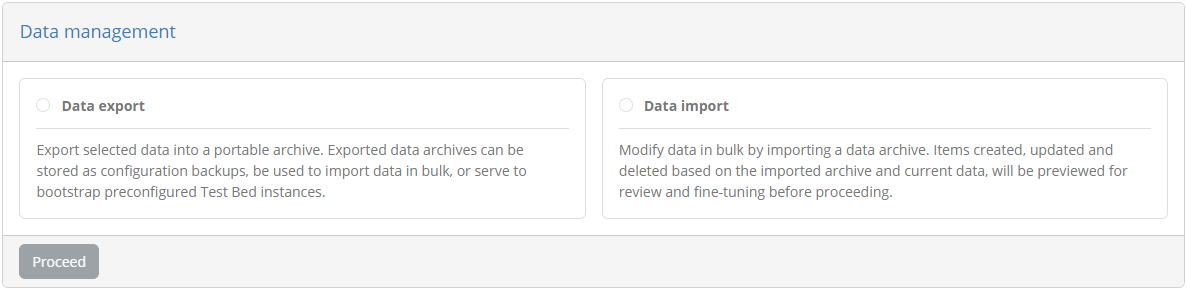
Export data
To export data select the Data export option from the data management screen.

The first choice you need to make is the type of data you will be exporting. This is defined by the Data to export choices and can be:
Domain configuration: Select this to export only the information linked to your domain (e.g. specifications, test suites).
Community configuration: Select this to export the full information linked to your community (e.g. custom properties, organisations) as well as its linked domain.
The second option can be viewed as a superset of the first one in that the community data can also include all information on the domain. It is important however to provide the distinction given that you may want to only export your testing configuration without any information linked to your community.
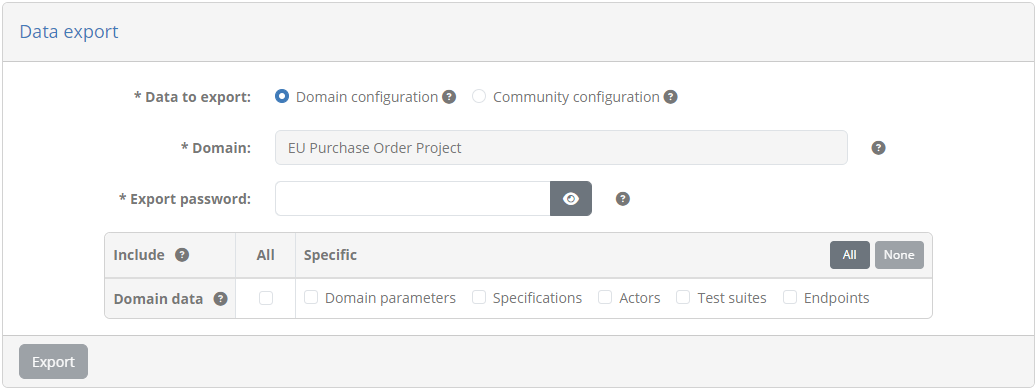
Selecting Domain configuration expands the form to provide information on the exported data. Doing so displays the name of the domain linked to your community that will be exported as well as additional configuration options.
Note
Community with no domain: If your community is not linked to a specific domain, you are presented with the full list of available domains.
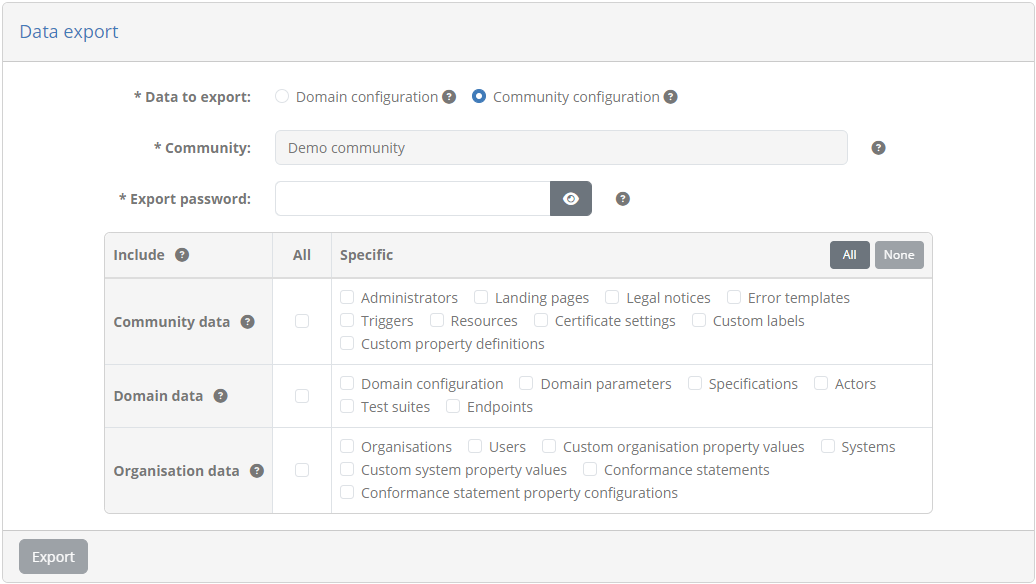
If you select Community configuration the form is similarly expanded to display the name of your community and the export options.
Regardless of your choice, the information you need to provide is as follows:
An export password that will be used to encrypt the export archive as well as any sensitive information that the archive would internally include. This password will need to be provided when you import the archive or if you manually open it.
The information to include in the archive presented as a table of available choices.
By default a domain export includes the basic information of the domain (its short name, full name and description) but you would typically further extend this to include the information you need. The available types of information are presented in the Domain data row and can be:
The domain’s parameters.
The domain’s test services.
The domain’s specifications.
The domain’s shared test suites.
Each specification’s actors.
Each specification’s test suites.
Each actor’s configuration parameters.
A community export includes in addition to domain data the community data and organisation data. By default it includes its basic information (short name, full name, notification options, self-registration settings and user permissions) but can similarly be extended. From the Community data row you may include the following types of information that form part of the configuration of the community itself:
The administrator accounts (only if the Test Bed instance is not integrated with EU Login).
The community’s landing pages, legal notices and error templates.
The community’s certificate settings.
The custom labels and custom properties defined for the community members.
The triggers used to drive automated tasks when important events occur.
The resources used in rich text content such as landing pages and test cases’ documentation.
Using the options from the Organisation data row you may also include data linked to the community’s members:
The organisations, including those that are defined as self-registration templates.
Each organisation’s users (only if the Test Bed instance is not integrated with EU Login).
The values provided by each organisation for the community’s custom organisation properties.
The systems defined by each organisation.
The values provided for each organisation’s systems relevant to the community’s custom system properties.
Each system’s conformance statements and statement configuration values.
Selecting one of these options will also ensure that any prerequisites are also included. For example an export including test suites will also automatically include the domain’s specifications and actors, checking these options automatically as mandatory. You may also check the All option from each table row to include all its relevant information or the All button from the table’s header to include everything. Clicking on None in the table’s header will uncheck all options.
At first glance it may appear odd to export organisations that are not only self-registration templates, as well as community administrator and organisation user accounts. Doing so is typically meaningful when replicating data across development instances and is also important when defining functional accounts for sandbox instances. Regarding exported user accounts in particular, and regardless of the use of encryption to protect account passwords, community administrators are advised to include them only in such specific circumstances and moreover, only when these are linked to functional accounts defined by them. It is important to note that any sensitive information included in exports, apart from being stored as one-way hashes to begin with, is encrypted using the archive password and stored within the archive which is itself a ZIP archive encrypted using AES encryption with a 256-bit key strength.
Once you are satisfied with the export settings click the Export button to produce and download the data archive.
Note
Exporting specific data: During the export it is not possible to select individual data items to be exported (e.g. a specific test suite), only types of data. Such fine-grained selections can be made as part of the import review process.
Import data
You import data by means of the Data import screen, that you access by clicking the corresponding link from the menu.

Carrying out a data import is a two-step process:
You first select the archive to be imported and provide the overall settings for the import.
Once the archive is uploaded you review the modifications it will make, confirm and complete the process.
Step 1: Select the data archive
Similarly to the data export, the first choice you need to make is on the type of import you want to carry out. You have two choices:
Domain configuration: Select this to import domain information (e.g. specifications, test suites).
Community configuration: Select this to import community information (e.g. custom properties, organisations) as well as its linked domain.
Choosing the type of import to carry out is important given that the data archive you want to import from may include additional information you would want to skip. A good example is when you have an archive containing a full community export but you want to import only the data linked to its domain.
Selecting one of these options expands the screen to present additional information and settings.
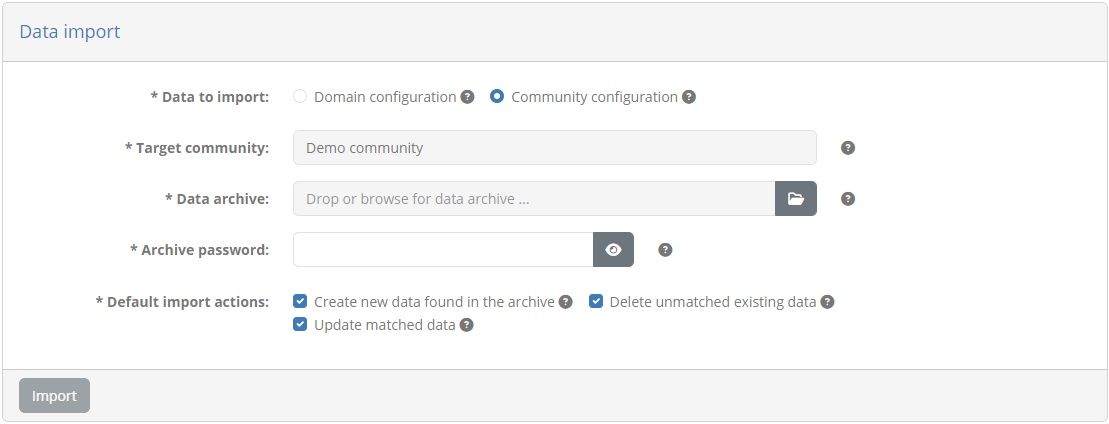
Depending on whether you chose to import a domain or a community, you see your own domain or community presented as the target. Following this you are prompted to provide the data archive to use as well as the password that was set during the export to encrypt it. Finally you are presented with a set of default import actions that will determine how data is to be processed. These options are specifically:
Create new data found in the archive: This will flag for creation all data that exists only in the archive and not the target Test Bed instance.
Delete unmatched existing data: This will flag for deletion all data that is found in the target Test Bed instance for which there is no match within the data archive.
Update matched data: This will flag for update all data that exists both in the data archive and the target Test Bed instance.
These options refer to the matching between data that exists within the archive and the target Test Bed instance. This matching is based on information such as names (e.g. a specification’s short name) which should be sufficient to identify it although not always guaranteed to be unique. For example, a specification’s actors always have a unique identifier, whereas there can be no guarantee on the name of an organisation. Although duplicate information is not typical, community administrators are advised to always review the processing actions that will result from an import.
Finally, it is important to highlight that the options set as default import actions only affect how data is flagged to be processed. You will always have the possibility to review this as well as override any specific processing actions as part of the import’s review.
Once you have provided all requested information for the import you can proceed to the next step by clicking the Import button.
Note
Data archive versions: If you import a data archive that was made for an earlier Test Bed version this will automatically be migrated to the latest version.
Step 2: Review and complete the import
In this screen you see the detailed actions that will be carried out as a result of the import. Actions are displayed under two main categories, Domains and Communities that are displayed as follows:
The Domains group is displayed if you are importing a domain or a community that is linked to a domain.
The Communities group is displayed if you are importing a community.
Next to each group you also see the count of its items which at the top level will always be 1.
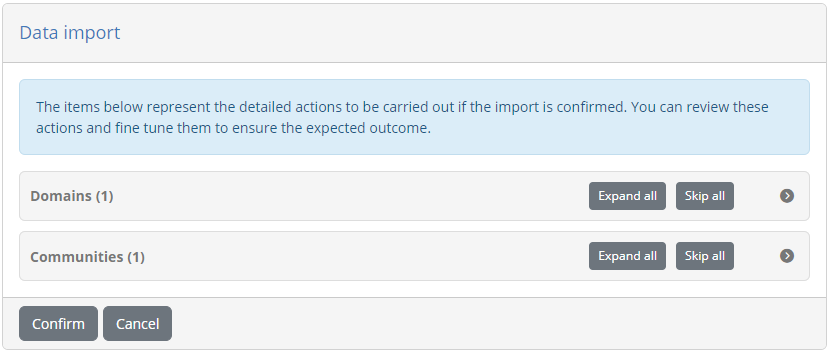
Actions are displayed in a tree structure reflecting the data they represent. You can progressively expand each group and included item by clicking its entry in the tree. Clicking again results in the item being collapsed. At any level you may also click the Expand all button at the right side that will expand all items starting from the point you selected. Note that collapsing an item collapses also all child items.
The displayed items are organised in groups and individual data items. The groups provide an overview of the type of data as well as the count of individual data items. Data items on the other hand represent each a processing action that will take place on specific data, and correspond to the result of the import taking into account data from the archive as well as existing data in the Test Bed.
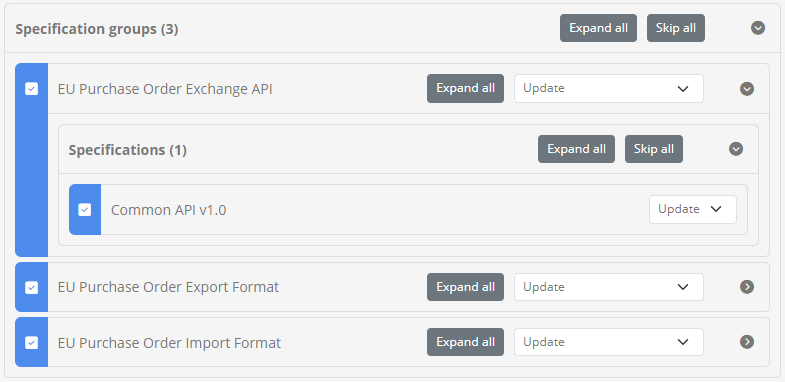
When reviewing the processing actions to be carried out it is important to identify where each actions comes from. This is done by means of colour coding and an icon displayed in the left side of each data item. The available processing actions for each data item depend on its source, with the default proposed action per case determined from the settings you provided in the previous step. Specifically:
Blue item (marked with a tick): Data that was found both in the archive and in the Test Bed. You may choose to update the data, process only dependent child data, or skip the update altogether.
Green item (marked with a plus): Data that was found only in the archive. You may choose to create the data or skip it.
Orange item (marked with a minus): Data that was found only in the Test Bed. You may choose to delete the data or skip it.
From the above you likely see that the items matched both in the archive and the Test Bed (marked with blue) offer an additional option of processing only child data. This is useful if you don’t want to update the matched data item itself (e.g. a specification) but want to continue processing dependent data (e.g. the specification’s test suites).
Selecting to skip a data item means that the import process will ignore it. A skipped item appears greyed-out and with a strike-through to make this more clear. When you choose to skip a data item with children or a complete group of items, this will extend also to any and all child data. In this case skipping child data is considered as being forced and is displayed as an action you cannot override.
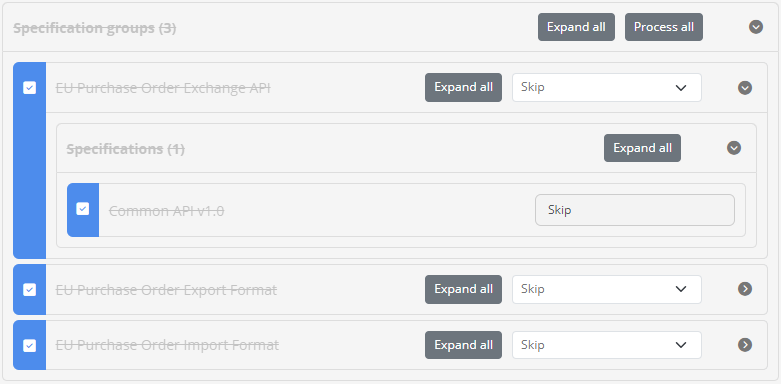
As mentioned earlier, in the case of matched data (blue items) you can choose the option to skip but process children that will not update the data itself but will continue to process normally all child data. You will notice that in this case only the parent data item is greyed-out whereas child items allow you to determine their actions.
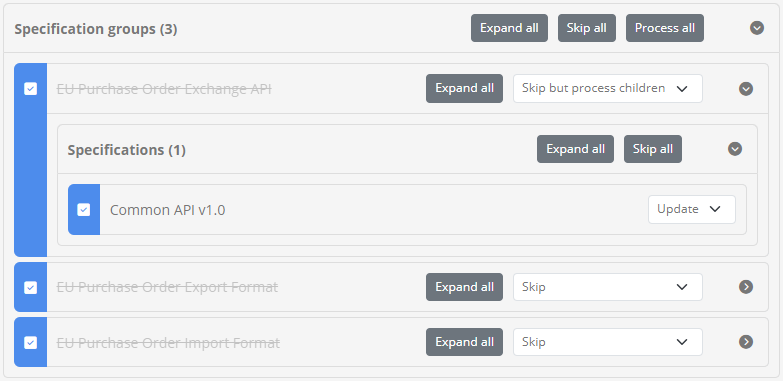
At the level of a data item group you are also presented with actions that apply to the complete group. You can specifically choose to Skip all its items, an option presented if at least one item is to be processed, or Process all if at least one item is set as skipped. A good example of when such controls are useful is when you want to completely skip the import of certain types of data (e.g. skip test suites).

Using these controls you can review at a very fine level all changes that will be carried out from an import and adapt the processing according to your intended result. Going into this level of detail is something you can typically skip when making an import into an empty domain or community, or when you want the result to reflect fully the data in the archive. A detailed review is nonetheless critical when targeting an existing domain or community that is currently in use to ensure there are no unwanted side-effects.
An important final note is that during the time it takes for you to review the actions and confirm the import there may be changes introduced in the relevant data. For example, you may be importing a conformance statement for an organisation that in the meantime is created manually by another user. The review you are making is linked to specific data and will never affect data that was not reviewed. For example, if you are deleting Test Bed data not found in the archive, this will only be the data you have reviewed, with any additional non-reviewed data being ignored.
Once you have completed your review and adapted the import actions click the Confirm button to proceed. Doing so will complete the import and, once finished, take you back to the import screen. Alternatively you can cancel the import by clicking the Cancel button.
Define a sandbox instance
An interesting use case that is made possible through data exports is the definition of sandbox instances. A sandbox is a Test Bed instance that is installed by a user and that is pre-configured to make available test scenarios and development tools. The purpose of such a sandbox is typically not formal conformance testing but rather to provide a set of test cases as utilities to be used during development. The Test Bed offers a perfect mechanism to provide scenario-based development tools but this needs to be done in a manner that is as streamlined as possible. This is made possible by means of importing data archives.
Step 1: Prepare the sandbox data
A sandbox’s configuration is basically the full configuration linked to a domain and a community. As a first step you would prepare this in a Test Bed instance you are using for development purposes to which you connect as a Test Bed administrator to have full control. To prepare this proceed as follows:
Create a new domain in which you include your testing setup. It is advised to use a new domain for this to keep things separate from your normal setup.
Create a new community to define settings such as labels and custom properties.
Define an organisation with a user account that users will be using from the sandbox to launch tests. If you want that users set a new password for this you could also set a one-time password.
Define a system for the organisation with conformance statements to allow sandbox users to immediately start executing test cases.
Provide any configuration values needed to ensure that the tests can immediately be used. This may include domain parameters, organisation and system properties as well as conformance statement configurations.
Once you are happy with the configuration proceed to export the complete community and its domain.
At this stage you have a data export you can use that contains all the configuration needed to start executing tests. The next step in the process is to use this data archive to setup a sandbox instance.
Step 2: Prepare the sandbox installation
A user setting up a sandbox instance will be expecting a streamlined setup experience. In theory, one could use the data archive you prepared in the previous step by (a) installing an empty Test Bed, (b) connecting using the default Test Bed administrator account, (c) creating an empty domain and a community linked to it, and (d) importing the community. This however represents a multi-step process that seems more like a workaround rather than a streamlined setup.
To simplify this process the Test Bed can be installed with configuration that enables advanced sandbox support. You have two options available depending on the approach you want to make available:
Automatic sandbox setup: The sandbox data is set up as part of the Test Bed’s installation.
Manual sandbox setup: Once the Test Bed is installed the user is prompted to provide the data archive.
Approach 1: Automatic sandbox setup
This approach sets up the sandbox data as part of the Test Bed’s installation. It is the simplest approach given that users would simply install the test bed and get started. However, to use this approach there is a prerequisite and a caveat:
Prerequisite: The Test Bed sandbox instance needs to be installed on an operating system that allows direct access to its filesystem for Docker containers (via volumes).
Caveat: The password used to generate the export needs to be provided as part of the Test Bed’s installation script.
In short, to follow this approach you would prepare the Test Bed’s installation script according to your needs and provide alongside it the data archive to use for its initialisation. The archive and its password are provided as input to the Test Bed, allowing it to read and process it automatically upon its initial run.
The Test Bed’s overall installation is driven through Docker and specifically Docker Compose. Make a copy of the installation script provided in the Test Bed’s installation guide and adapt it as needed to include additional services you need such as validators. What is important for the sandbox setup is the additional configuration to be done to the gitb-ui service. Specifically:
services:
...
gitb-ui:
...
environment:
...
- DATA_ARCHIVE_KEY=the_archive_password
volumes:
...
- ./data/:/gitb-repository/data/in/:rw
The important points here are:
The
DATA_ARCHIVE_KEYenvironment variable that is set with the password used for the data export.The volume that maps a folder
datanext to the script to a specific location within the container.
Next up, you need to create the data folder and copy within it the data archive prepared previously.
To keep things simple, the data folder should be created next to the installation script so that it can be referred to from within the
script using the relative path ./data/. As a final step ZIP the installation script and data folder to create a single installation
bundle and provide it to your users.
On the side of the user the installation process is very simple:
The user extracts the installation package you provided in a target folder.
From within the target folder the user installs the Test Bed by issuing
docker compose up -d.Once the installation completes the user can connect to the Test Bed using the account(s) you have defined and start executing tests.
Approach 2: Manual sandbox setup
The manual setup approach requires an extra step by users as part of the installation but offers important benefits:
It can be ubiquitously applied as it has no prerequisites on how Docker containers access the host file system.
It avoids the need of including the archive password in the installation script.
The Test Bed’s overall installation is driven through Docker and specifically Docker Compose. Make a copy of the installation script provided in the Test Bed’s installation guide and adapt it as needed to include additional services you need such as validators. What you need to do in this case is configure the gitb-ui service to expect a data archive upon first connection:
services:
...
gitb-ui:
...
environment:
...
- DATA_WEB_INIT_ENABLED=true
The important point here is the DATA_WEB_INIT_ENABLED environment variable that is set to true. Doing so will instruct the Test Bed
to prompt the user for the data archive upon first connection. To complete the preparation, bundle together the installation script and the
data archive prepared previously that you can then provide to your users. You need to also communicate the archive’s password as this
will be requested for the setup.
From the user’s point of view the installation process involves the following step:
The user copies the installation script you provided in a target folder.
From within the target folder the user installs the Test Bed by issuing
docker compose up -d.Upon first connection the user is automatically prompted to supply the data archive she received as well as its password.
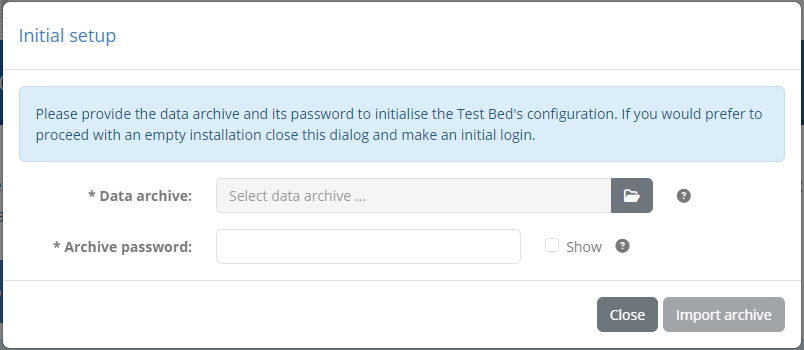
Note that compared to the import screen you access within the Test Bed, there is here no selection of target domains or communities, nor choices for default import actions. Upon clicking the Import archive button the archive is processed to create a new community linked to a new domain with all contained data flagged for creation. Once this initial import has been completed, the user can log in using the account(s) you have defined within the data archive. Note that this initialisation process can only be carried out once.
The user may close the data initialisation popup by clicking the Close button. One reason to do this would be to skip data initialisation and proceed with an empty Test Bed instance. To do this the user can close the popup and proceed to make an initial login using the Test Bed’s default administrator account. Note that if the dialog is closed by mistake, the user can always make it reappear by refreshing the screen (assuming no login has been made in the meantime).
Note
Automatic vs manual sandbox setup: Choosing the setup approach to follow (or potentially allowing both) is up to you. Automatic setup requires no user interaction but assumes an operating system that runs Docker natively, allowing it to directly read files from its filesystem. If this is a problem, or if you want to avoid including the data archive’s password in the configuration file, choosing the manual approach is the best option. As a rule of thumb the approach that is guaranteed to work in all cases is the manual setup.